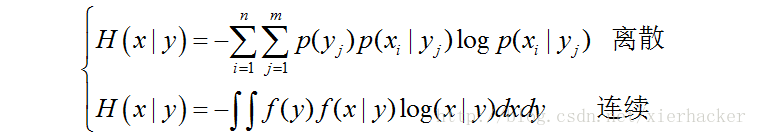
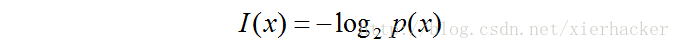
 4 |: {; F- a8 q6 Y: \4 o$ |* l2 s( g$ @
4 |: {; F- a8 q6 Y: \4 o$ |* l2 s( g$ @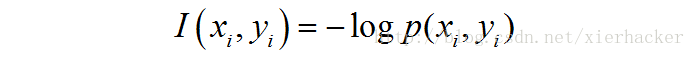
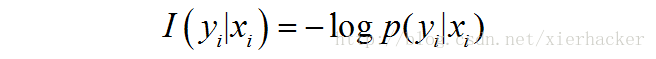
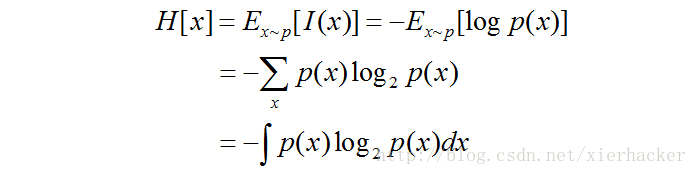
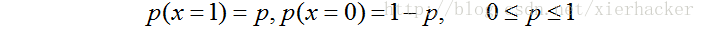
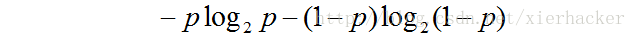
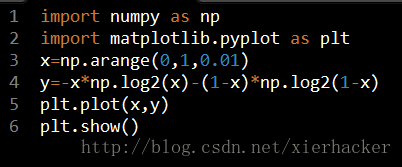
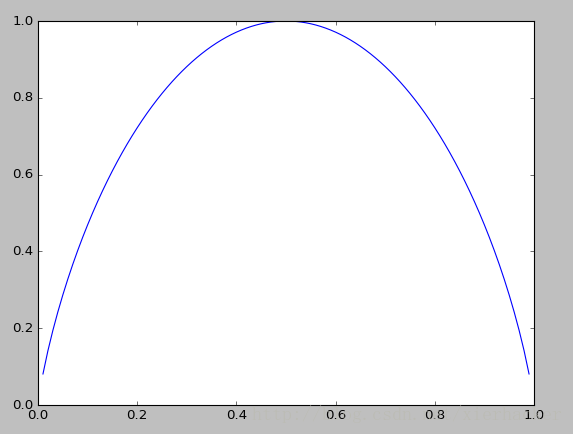 % Q; {5 x# l0 k# s% T! e7 z0 G* m
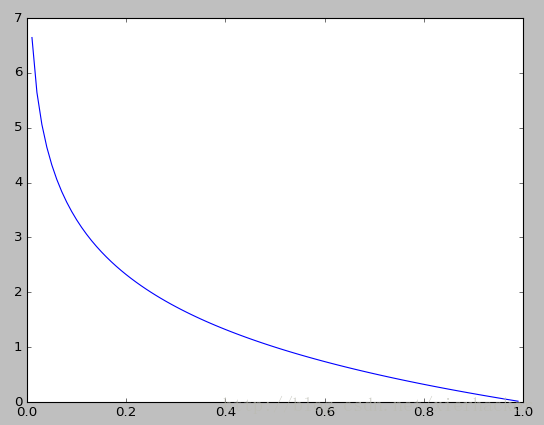
% Q; {5 x# l0 k# s% T! e7 z0 G* m从图中可以知道:
1.当p=0或者p=1的时候,随机变量可以认为是没有不确定性. 3 ~7 W# T$ b+ p9 v+ [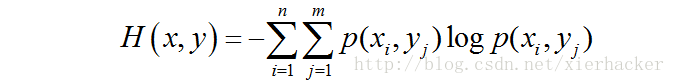 ! o, i+ Y: R# f! v0 ~) o
! o, i+ Y: R# f! v0 ~) o同样,复合熵的公式还可以推广到连续变量和多个变量的情况。这里就不写了。
条件熵:
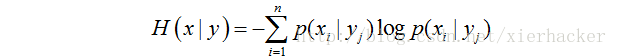
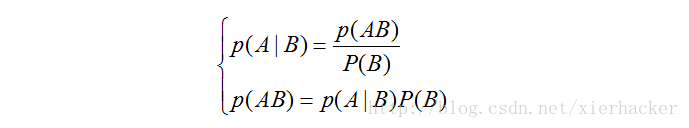 7 F" H8 v* B6 _& _" E2 T* l
7 F" H8 v* B6 _& _" E2 T* l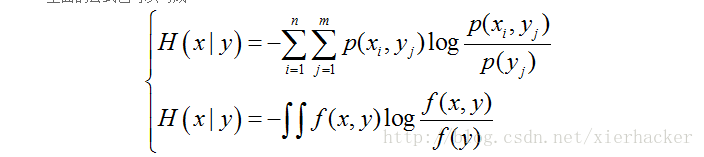 9 F- g/ c. M6 X4 Q, b# S
9 F- g/ c. M6 X4 Q, b# S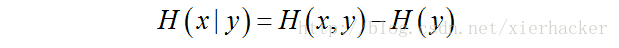 ) M: x$ C; S/ c- H% S% R
) M: x$ C; S/ c- H% S% R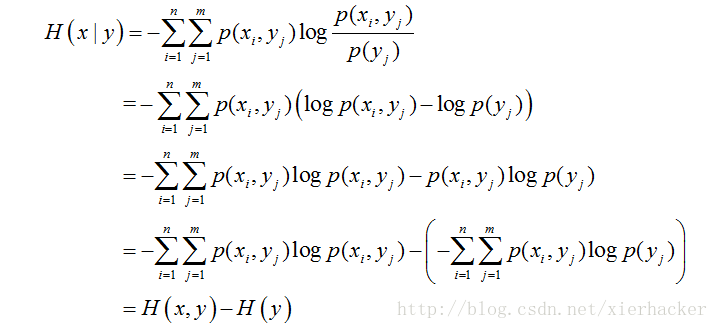 0 C. Z" H1 d% U0 t* y
0 C. Z" H1 d% U0 t* y| 欢迎光临 数学建模社区-数学中国 (http://www.madio.net/) | Powered by Discuz! X2.5 |