
2018-11-2 08:43 上传
下载附件 (163.8 KB)
 ; t8 \. m0 p8 Q+ @9 v
; t8 \. m0 p8 Q+ @9 v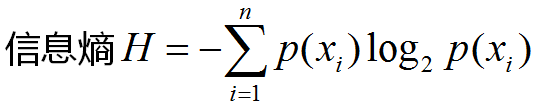 0 }3 h* s/ E: O! d: z1 W
0 }3 h* s/ E: O! d: z1 W ( v! O* H X" K1 ]/ Q8 S) c8 ]; S
( v! O* H X" K1 ]/ Q8 S) c8 ]; S

 ' B- w/ Y" S. K9 N* m
' B- w/ Y" S. K9 N* m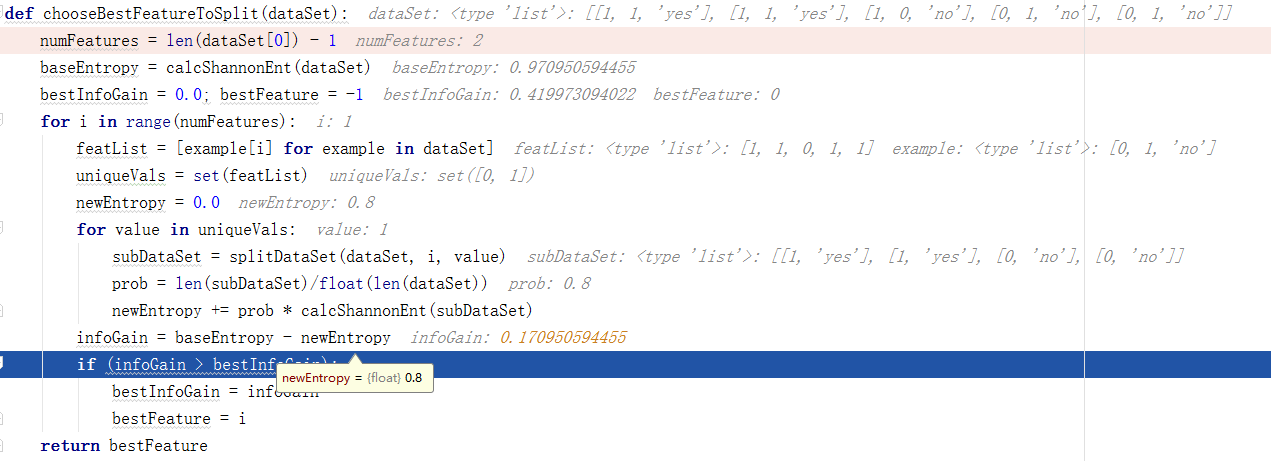 ; y9 z2 a d5 y6 z
; y9 z2 a d5 y6 z 0 ]/ R% M% ^+ J0 o+ w
0 ]/ R% M% ^+ J0 o+ w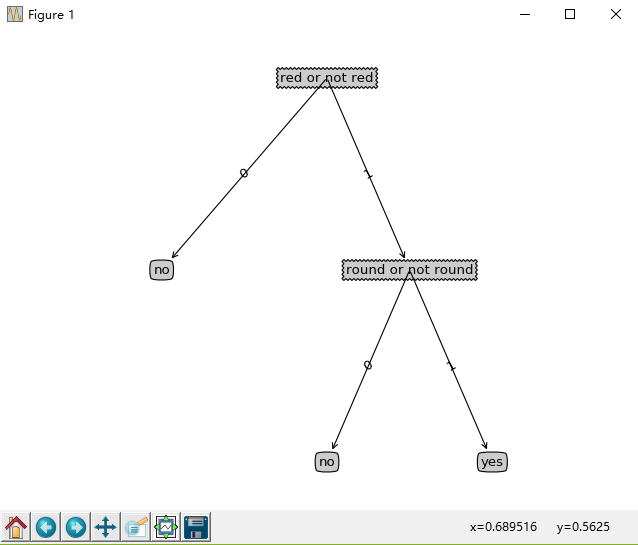 * B) |. r0 L/ X( `& t' T; P% K* g
* B) |. r0 L/ X( `& t' T; P% K* g| 欢迎光临 数学建模社区-数学中国 (http://www.madio.net/) | Powered by Discuz! X2.5 |