数学建模社区-数学中国
标题: 数学建模方法-灰色预测法 [打印本页]
作者: 杨利霞 时间: 2019-4-4 15:30
标题: 数学建模方法-灰色预测法
数学建模方法-灰色预测法一、引言 大家好,今天是第三天,前两篇博文用到的数学建模方法应用的数学知识还比较少,在这一篇章,需要的数学知识变多了,大致需要一些高等数学中导数部分的知识,大家如果忘了的话记得自己去补哈。好言归正传,今天要讲的到底是什么方法呢,就是那个很出名的“灰色预测模型”啦。好了开讲咯!
二、灰色预测模型2.1概念2.1.1 灰色系统、白色系统、黑色系统 在讲灰色预测模型的概念时我想先跟大家介绍三种系统。
- 白色系统:指一个系统的内部特征的完全已知的,即系统信息是完全公开的。
- 黑色系统:与白色系统相反,指一个系统的内部信息对外界来说是一无所知的,只能通过它与外界的联系来加以观测研究。
- 灰色系统:介于白色系统和黑色系统之间,即系统内一部分信息是已知的,但另一部分信息是未知的,系统内各因素间有不确定的关系。# y6 ~$ X: l2 z3 U4 T- S. ?
一般我们在生活的过程中,大多遇到的系统是灰色系统。因此,我们就需要利用灰色系统内那部分公开的信息,来建模推测出隐藏的信息。这就是灰色预测模型。
2.1.2 灰色预测法- 灰色预测法是一种预测灰色系统的预测方法。* s- R: O$ ?- {9 n6 n/ o. ?: c# m$ H1 o7 y
目前常用的一些预测方法(如回归分析等),需要较大的样本,对于少样本的情况就会造成比较大的误差,使预测目标失效。而灰色预测模型所需的建模信息少、运算方便、建模精度高,因此在各种预测领域都有着广泛的应用,是处理小样本预测问题的有效工具。
- 灰色预测通过鉴别系统因素之间发展趋势的相异程度,即进行关联分析,并对原始数据进行灰色生成来寻找系统变动的规律,生成有较强规律性的数据序列,然后建立相应的微分方程模型,从而预测事物未来发展趋势的状况。
) i& t) R- y1 C) M" Z
2.2 关联分析
首先什么是关联分析呢,实际上,关联分析时动态过程发展态势的量化比较分析。所谓发展态势比较,也就是系统各时期有关统计数据的集合关系的比较。
举例来讲,某地区2010-2018年的总收入与养鸡和养猪收入资料如下表格。
" j! _6 z& y9 d6 g3 U
9 X* _2 N, Q4 Y/ j! Q| | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 |
| 总收入(万元) | 16 | 21 | 22 | 21 | 21 | 20 | 20 | 19 | 25 |
| 养猪(万元) | 12 | 15 | 14 | 16 | 14 | 16 | 13 | 10 | 15 |
| 养鸡(万元) | 4 | 6 | 8 | 5 | 7 | 4 | 7 | 9 | 10 |
8 O: ]5 y6 r. U! Y6 U7 p
根据上述表格,可以画出曲线图,如下:
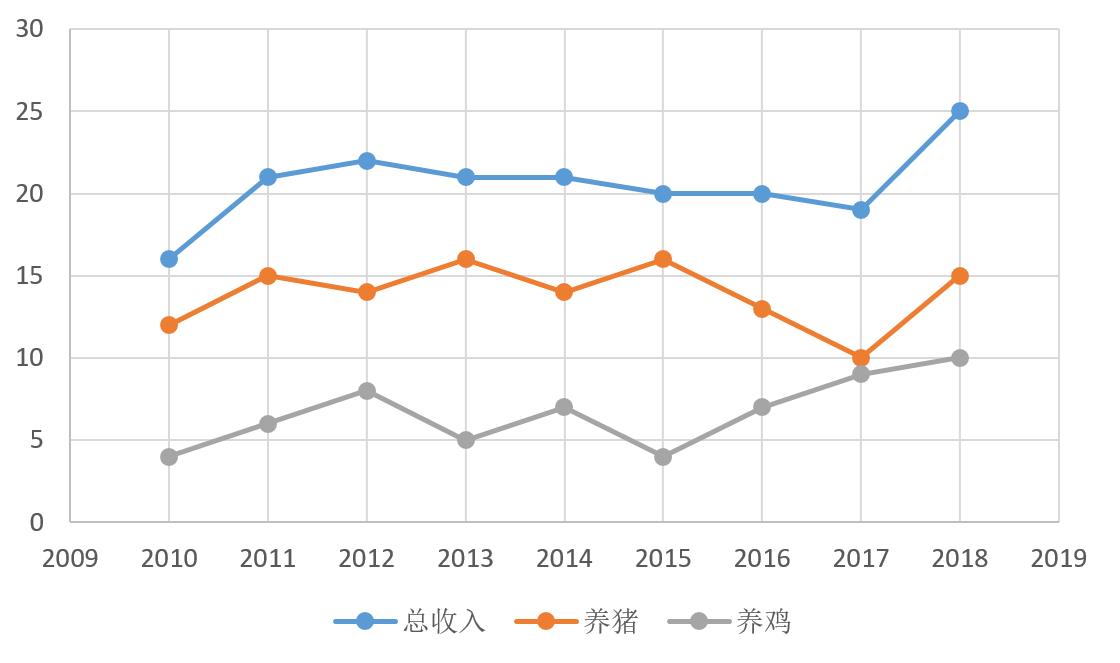
) I( O5 T5 a0 |, l9 ]' J' n7 `
由上图易看出,蓝色曲线 (总收入)与橙色曲线(养猪收入)发展趋势比较接近,而与灰色曲线(养鸡收入)相差较大,因此可以判断,该地区对总收入影响较直接的是养猪业, 而不是养鸡业。
很显然,几何形状越接近,关联程度也就越大。但是,对于一些稍微复杂的问题,如果不容易画出图,那就很难通过直观的手法来分析。这时就需要我们的灰色生成方法了。
2.3 灰色生成 原始数据列中的数据,按某种要求作数据处理,这样的一种方法叫做生成。
灰色系统理论认为,尽管客观表表象复制,但必定蕴含某种内在规律的,关键如何去发现这样的一个规律。灰色生成就是为了从灰色序列中去找出内在的规律,从而能判断事物的发展趋势。
常用的灰色生成法有:累加生成、累减生成和加权累加生成。接下来我们就来以此介绍它们。
(1)累加生成(AGO)
假定原始数列为x(0)=(x(0)(1),x(0)(2),⋅⋅⋅,x(0)(n))
,令
x(1)(k)=∑ki=1x(0)(i) , k=1,2,⋅⋅⋅,n
# k# n( z: D j5 p; y4 bx(1)=(x1(1),x1(2),⋅⋅⋅,x1(n))
* X: T9 A. T8 Z/ E4 b 则称x(1)
为数列x(0)
的1次累加生成数列。若继续推广,有
x(r)(k)=∑ki=1x(r−1)(i) , k=1,2,⋅⋅⋅,n, r≥1
: S: t& i* O) k( ]1 f" ~
x(r)(k)
称为x(0)(k)
的r次累加生成数列。
(2)累减生成(IAGO)
假定原始数列为x(1)=(x(1)(1),x(1)(2),⋅⋅⋅,x(1)(n))
,令
x(0)(k)=x(1)(k)−x(1)(k−1) , k=2,3,⋅⋅⋅,n
5 v: K* f' e7 h. ~9 P
则称x(0)
为数列x(1)
的1次累减生成数列。可以看出,通过累加数列得到的新数列,可以通过累减生成还原出原始数列。
(3)加权邻值生成
假定原始数列为x(1)=(x(1)(1),x(1)(2),⋅⋅⋅,x(1)(n))
,称任意一对相邻元素x(0)(k−1),x(0)(k)互为邻值。对于常数α∈[0,1]
, 令
z(0)(k)=αx(0)(k)+(1−α)x(0)(k−1), k=2,3,⋅⋅⋅,n
* i: W. A1 n3 T, b$ P; X: _
由此得到的数列称为邻值生成数,权α
也称为生成系数。特别地,当生成系数α=0.5
,则称该数列为均值生成数,也称为等权邻值生成数。
2.4 灰色模型GM(1,1) 灰色模型是利用离散随机数经过生成变为随机性被显著削弱而且较有规律的生成数,建立起的微分方程形式的模型,这样便于对其变化过程进行研究和描述。
G表示grey(灰色),M表示Model(模型);
首先,定义x(1)
的灰导数为
d(k)=x(0)(k)=x(1)(k)−x(1)(k−1)
( V& g: C8 @; A6 Z2 X& _+ [ 令z(1)
为数列x(1)
的邻值生成数列,即
z(1)(k)=αx(1)(k)+(1−α)x(1)(k−1),
& b& ~( S* D0 E6 r' Q& }
好的。接下来我们要定义最重要的一个方程了,就是GM(1,1)的灰微分方程模型:
d(k)+az(1)(k)=b
或 x(0)(k)+az(1)(k)=b
$ [* }0 Y6 a1 L: {9 z% K 其中,x(0)(k)
称为灰倒数,a称为发展系数,z(1)(k)
称为白化背景纸,b称为灰作用量。
将k=2,3,...,n
代入上式,有
* D. A1 T) z- `0 `8 D# t
x(0)(2)+az(1)(2)=b
1 s& Q- N- {* ^ E
x(0)(3)+az(1)(3)=b
! `/ x3 C/ C# D0 Y% C+ t- }6 A; Z⋅⋅⋅
: o! b+ q, q [7 w" X* Ix(0)(n)+az(1)(n)=b
0 o3 f7 |7 _/ V9 i A# _1 Q引入矩阵向量记号:
u=[ab]
Y=⎡⎣⎢⎢⎢⎢x(0)(2)x(0)(3)⋅⋅⋅x(0)(2)⎤⎦⎥⎥⎥⎥ B=⎡⎣⎢⎢⎢⎢−z(1)(2)−z(1)(3)⋅⋅⋅−z(1)(n)11⋅⋅⋅1⎤⎦⎥⎥⎥⎥
c( u- F' f! z# u+ _) ^' P$ p U
于是GM(1,1)模型可以表示为
Y=Bu
3 _, x+ H, _' T" K
那么现在的问题就是求a和b的值,我们可以用一元线性回归,也就是最小二乘法求它们的估计值为
u=[ab]=(BTB)−1BTY
- A" A5 m1 w9 v! ~2.5 GM(1,1)的白化型 前面我们定义的模型是在离散的情况下,那么针对连续时间t
,则之前的X(1)视为时间t函数,于是灰导数x(0)(k)变为连续的导数dx(1)(t)dt,白化背景值z(1)(k)对应于导数x(1)(t)
。于是GM(1,1)的灰微分方程对应的白微分方程为:
dx(1)(t)dt+ax(1)(t)=b
8 W7 Y5 C3 I$ x! S) J) c, h三、GM(1,1)灰色预测的步骤3.1 数据的检验与处理 为了保证GM(1,1)建模方法的可行性,需要对已知数据做必要的检验处理。
设原始数据列为x(0)=(x(0)(1),x(0)(2),⋅⋅⋅,x(0)(n))
,计算数列的级比
λ(k)=x(0)(k−1)x(0)(k), k=2,3,...,n
g" v7 G$ P) O( U& x
如果所有的级比都落在可容覆盖区间X=(e−2n+1,e2n+1)
内,则数列x(0)
可以建立GM(1,1)模型且可以进行灰色预测。否则,对数据做适当的变换处理,如平移变换:
y(0)(k)=x(0)(k)+c, k=1,2,⋅⋅⋅,n
1 b# X# s1 o% a: s% S 取c
使得数据列的级比都落在可容覆盖内。
3.2 建立GM(1,1)模型 当x(0)=(x(0)(1),x(0)(2),⋅⋅⋅,x(0)(n))
满足上面的条件后,我们就可以以它为数据列建立GM(1,1)模型,即根据Y=Bu求解出u=[ab]
。相应的白化模型为
dx(1)(t)dt+ax(1)(t)=b
0 }+ [/ I4 {% z2 t8 v
这是一个微分方程,可以求解得到:
x(1)(t)=(x(0)(1)−ba)e(−a(t−1))+ba
! s* ?# N( p& z! \" G; w( H5 C/ y8 {
于是得到
x^(1)(k+1)=(x(0)(1)−ba)e(−ak)+ba, k=1,2,⋅⋅⋅,n−1
' Z5 x; d8 T$ ^ t; k
因此得到预测值为:
x^(0)(k)=x^(1)(k)−x^(1)(k−1) , k=2,3,⋅⋅⋅,n
! L: ~, q- o0 q# M5 w: Y
3.3 检测预测值
模型选定后,一定要经过检验才能判定其是否合理,只有通过检验的模型才能用来作预测,灰色模型的精度检验一般有三种方法:相对误差大小检验法、关联度检验法和后验差检验法。下面主要介绍相对误差大小检验法和后验差检验法
3.3.1 相对误差大小检验法
ε(k)=x(0)(k)−x^(0)(k)x(0)(k), k=1,2,⋅⋅⋅,n
8 j h3 X3 h7 B0 A
如果对所有的|ε(k)|<0.1
,则认为到达较高的要求;若对所有的|ε(k)|<0.2
,则认为打到一般要求。
3.3.2 后验差检验法(方差C检验法)
- 原始数列:x(0)=(x(0)(1),x(0)(2),⋅⋅⋅,x(0)(n))5 u% W+ b4 |3 i- A0 f
- 建模后算出的数列:x^(0)=(x^(0)(1),x^(0)(2),⋅⋅⋅,x^(0)(n))
- 残差序列为E=(e(1),e(2),⋅⋅⋅,e(n))# g$ {9 H" x9 L$ X
2 p! G$ C! \; }9 H1 ^3 t' c
其中,e(k)=x(0)(k)−x^(0)(k), k=1,2,⋅⋅⋅,n
7 g0 U M" ?, X
记原始序列x(0)
及残差序列E的方差分别为S21和S22
,则
S21=1n∑nk=1[x(0)(k)−xˉˉˉ]2
# E+ b) S+ C( |: F5 B4 B0 y
S22=1n∑nk=1[e(k)−eˉˉˉ]2
/ g6 R5 {, X& e. Z$ M; H8 d1 y- L 其中,xˉˉˉ=1n∑nk=1x(0)(k)
,eˉˉˉ=1n∑nk=1e(k)
# x* x( \% M5 W4 I 则后验差比为:
C=S2S1
L- A$ ^! c3 ~4 N8 C 指标C
是后验差检验的重要指标。指标C越小越好。为什么这么说呢?这是因为,C越小就表明S1大而S2
越小。
那S1
大表明什么,它表明原始数据方差大,这也就说明原始数据的离散程度大。
那S2
小又表明什么呢,它表明残方差小,也就是残差的离散程度小。
因此,C
小就表明尽管原始数据很离散,但模型所得的计算值与实际值之差并不太离散。这样得到的数据可靠性就越强。这样讲是不是就懂啦。。
下面附一张精度检验等级参照表
) B( m. v1 z! s
( V! q5 f) @5 U& w# E- f! G' l8 W
1 D/ K5 U+ `% D: r- A9 |# B2 s0 f& K& y
$ ~+ r, g7 w# X3 @, F
, a* k6 Z/ K2 {7 s- S0 l k3 }0 a四、GM(1,1)模型的Matlab代码
0 Y" e% V: P ]1 g: Z1 d/ F' O; F' @5 y2 n c! p/ g. O0 o' H
%%构建GM模型计算出a和b
4 E( ?: s5 H( @, [* R% o
" G+ w+ F' O/ q1 R( @9 z6 b1 V7 g3 F
% b) U7 H6 M- f: j
- ! N! l# Q1 j/ x4 t/ ?- p
; O) u! N1 a6 b. J. a; f%建立符号变量a(发展系数)和b(灰作用量)- U; q+ v- A' H/ W6 k9 l
$ n) p1 D ]: L( Q0 ?& k$ o0 H) S! B+ B. A9 `
syms a b;* U3 z& l7 \5 j
- ; E) F1 @3 @' \, G0 y2 }, b
: u4 w9 C( O' B% U, ^9 Nu = [a b]';) [1 r# E) a, T6 c; c" v2 L
- . O# z/ c# m* |) L) x
9 x, P# a- u5 q3 ?: E9 `, ~% [) |7 w" z+ G
9 h7 l# D. [% N' r3 }# T7 q, Z: }% Z9 m
%原始数列X0
" [, d; b- B: o9 ?# l. I9 a( y
1 b& X* V6 y# x2 h/ \/ e7 o
2 U6 x0 Z& [' c) SX0 = input('请输入数据');
7 M2 J( T1 ?7 q( A3 G6 {- $ G" w1 K8 g2 c- k1 k0 b% `7 @& m
" M+ U% Z- H$ E! C: I9 k" v
n = length(X0);
. J. K5 J$ i# Z" S - # o7 q. N3 ~5 ?
6 b3 C0 m' C$ I$ o) S7 ^
2 S: a) `/ W0 m# [, Z
% L( m. D* @9 k2 A# W+ i$ p
6 V; C" E" s0 L%对原始数列X做累加得到数列X1
N$ t6 V* J1 ]9 S: Y% Q- % l. m, G" t- `$ _* V
0 H' L0 Z8 k. B+ EX1 = cumsum(X0);2 c! a8 ]% q5 D8 [1 O; G# t
1 [( I9 P- @4 O
1 G* _% h; h# O; H: p. l$ R9 @& y5 J, S
, \+ e2 T( u* s
- m8 w" }, c8 h% [%对数列X1做等权邻值生成Z14 Q I4 A T/ |2 G6 H ]4 Y) `9 l
- 5 f0 s* [: ^; b6 X' U# A$ Y4 B
( U! Z' l* r5 C3 O7 e. e9 y, k$ i0 Tfor i = 2: n. Q! ], y6 P( o/ v& F
7 G C1 A/ ^: T4 S7 o1 }3 U7 C* ]6 z1 ]3 E% n H
Z1(i) = (X1(i) + X1(i - 1)) / 2;; B- z, Z9 W; _: l7 H8 J1 G* s% v
- & B8 n7 G( r, @5 n; C! _6 ^ s
& q2 L" r/ {+ m, E3 I$ v8 B w
end5 I3 c2 S# ]+ o* s) G
- - S6 A- i# L4 M* |" T3 L7 t
0 y" k2 K5 S; \( n, X: W
Z1(1) = []; %去除掉第一个元素! T* o5 K2 M1 B. s4 E/ A1 {
: w9 E2 B" y, I) |
/ V; g7 e! b$ h" `7 k- W4 z e3 d" \8 y p
- 2 _: ~' b t$ ?4 w0 T2 L: x8 L
6 ]. X6 g4 W$ |, u0 Q0 ^0 g
%构造数据矩阵' z4 H, C1 L) A$ r( h2 c2 `) A
- 5 ]& y, v. L0 i9 [; r6 `. ~
: Y G \, b7 D# b* \B = [-Z1; ones(1, n - 1)]';
* p0 j& ?) R0 A: j$ l' Y1 ^
% K7 h5 e& C0 p* m' T9 W. w% c
2 `% a) E/ N: ^. G$ A! o& kY = [X0]';) \ L0 p( E3 a3 S9 O4 y
- . y% j; F& X7 d$ E0 B5 f) J* D
- v8 b( \2 ~- ~+ v( V8 x, @" ~7 ^Y(1, :) = []; %去除掉第一个元素* b6 v' ?8 T& N9 O9 ]2 g% N O
% T1 f A/ y! W8 d2 d
9 N# b+ u0 J5 R I- o* _; f% F$ L$ ~, l. N; {: j" `/ N7 U2 J
, w4 f% B1 ] Z) a& h8 ^4 v! `( H! X3 e- o5 s2 L# u! L
%利用u = inv(B'*B)*B'*Y来求解
( z' \2 y+ B2 s6 V0 Z- 1 A+ h& F7 b b- d: I. p
# r$ ]' g! h6 `" \$ {u = inv(B'*B) * B' * Y;
2 d: e/ ?- l9 @ r% U
& t. @9 g9 `5 v- C+ ?6 D! C j# Q# r% V. S- F- k; H
a = u(1, :);- g- K) B% M: a' g5 L8 ?5 ]6 ?
- ; C. W2 X; P/ T( Z" v( ~% L
% u. Z+ f' C1 \& ob = u(2, :);, E4 e; _* a; D! S5 ]1 y
- 2 G! ]5 b) c) ~# L
* x3 T! p$ f4 x! V; |# v, h5 R" S
0 V" r0 i0 ~4 P+ M3 N' G: C0 t$ x1 J9 P( g
0 s. V/ p1 J# P. T1 e$ S+ W7 H
- 8 t, u, i! X- `. U1 Z7 H0 ?
+ i+ ?0 B: `+ O4 T2 M' D( G
%%预测后续数据, C0 j% j. |, L2 ?9 t
- ) e+ O% y; K1 B! y3 z
0 o$ t+ _- t/ V# `; D+ V. `
0 i: {8 V/ f, l" E - 3 n1 F* h8 {9 ^$ s; j
+ l A9 p) I9 }6 b%p是预测后续的数据量,根据情况可更改
; R. g( Z" Z! z1 ~9 f5 o - 9 x2 h( E: p0 F& q9 \
3 o( y+ T4 r+ Xp = 3;
; B% \9 d3 \. V! V! t
4 N7 N4 x' m9 k# ?
H2 R% ^8 R+ r$ H8 t: _, @%构建预测数列F
0 `# m Q8 F$ k3 G8 H# }' W6 \' W- 5 v1 }& [. c! d# ^' m- ]
/ I' N& [: c0 _, T% |& r5 `" ~0 _F = []; F(1) = X0(1);1 h1 }1 K1 r7 b5 L1 A( S6 P, a
; L5 ?/ l( f4 R' B% T$ D8 D+ e: ~, M; A6 s9 z8 o; ^+ Z
for i = 2: (n + p)
( n$ ^9 H8 c* ~7 {5 j" j J( I
4 Z( o5 w; f5 W3 {. ?! N4 \0 V4 t# d1 j f
F(i) = (X0(1) - b/a) * exp(-a*(i-1)) + b/a;
, F2 l: {8 O& a) s& Q' K4 X- i
0 Z8 h* v$ O0 V1 U- ?
& }5 y2 q( R! m; V$ jend% s$ k/ V. y7 u% N
- . |9 E, c# E- _6 ~ u& T
# H6 t5 k) U7 k& M- ?/ L) D: E0 p7 m5 n/ c9 R5 D% S g
- + V( S5 Q& K* u1 n+ c; b
) ~# U4 [: w/ o, T5 E, `* _
%对数列F累减还原,得到预测出的数据
$ h, j2 j- }& Z5 U
/ e# P( `$ D2 M$ N+ |- ^4 k0 ?# t5 O, H! R8 u/ e# D
G = []; G(1) = X0(1);
# _( d8 X) q% n: p, ?$ d. C
O# @6 ~* A; j6 s% L! E, L
! G) {7 V; h' q" e1 Q& S: kfor i = 2: (n + p)
- k5 h2 ]5 A5 u5 r( A7 b
- L% N; x2 ?( O7 h) M& l9 m9 l7 B T' N
G(i) = F(i) - F(i-1);
% t1 v! [( q$ ]$ p- " I" {. h( o/ I6 m c) @& E# q
: ]8 {* D+ h: k3 l4 Z& ~
end/ `0 }# G) a; Y& Z
! K3 j, _# i2 S7 {3 O' ]$ S) E, T6 ~; O* v& c2 M
/ Q# p* ]. ~. \# i7 o
) n+ b" F" x5 H7 I, B
- X9 \0 P1 J4 a1 o2 \) ?disp('预测到的数据为: ');# L- k9 |( m: L* b8 i; q5 z
3 d. e* ?& D6 \
/ e v$ w6 ^9 U5 u5 iG1 H& c+ [4 U+ Z; [
% N& r' Z; q' f4 u
0 o4 Q1 |2 u5 W ~3 S0 @: G5 |9 [& I: J& }
/ B6 c1 B& G, G: G N4 F& {4 h4 g, H% j1 l( Z
%%模型检验
" z& ~6 K X) G4 G0 W- ( r) c$ Q9 F$ ~6 G3 v
4 t) v: I+ m ^/ ]) _* g3 ^$ h
8 ?! Q7 K' `4 c7 h5 |
& c# |/ p3 P' a5 `) y) t; U {* B/ Y( ^# U! r8 m/ _
H = G(1: n);: z2 ^ [6 l8 u. h) d
4 i' \1 s& S/ b: |$ j. \4 E( W4 O: G/ z2 o
%计算残差序列+ W* W; u& @3 W | T
- - L) T- n3 c3 Z3 r
/ B, A! m6 m5 k: g
E = X0 - H;
5 ^/ e/ F" H# D+ V8 V
2 S# z1 M$ K( l6 C3 \0 [' J0 l3 s* i
: m8 ^% V8 p, [9 e! v6 D! ?6 }
- 3 r+ Z- B- L5 O! b# V! Z
; k& V- q0 p1 j" q%法一:相对残差Q检验
1 l9 t4 _1 P) ?
& ]2 ~# i! I) M5 W( [- [3 F& J. y& i: U: ] n
3 w! T+ q4 \' h) L; I! \
* _: S# g; C* o. G: F' k; v, Q; @' u+ N
%计算相对误差序列6 c* d" M( {, x. H2 H2 [
- & M8 X: n; }! ~: c( S
" J* {( h. X7 E, b( q+ h& n; u3 `
epsilon = abs(E ./ X0);8 z0 |% Z! _9 q1 D. K7 P# Z5 n8 [& ~
8 r2 e7 E% M: E8 S2 q, G$ r4 A. P# w7 ?( l* n! {
%计算相对误差Q5 N9 V# z; m# N$ }
1 f2 e+ i) r& i$ Y
- Y8 p8 }& B7 P: v% \disp('相对残差Q检验: ');
& h1 T1 C o# U7 j
+ k' K& v, u7 I6 _+ s
3 s5 P* ^; K d( M) |, _4 eQ = mean(epsilon)
+ s$ E' V4 D ^4 l- - F+ H% b" z [: L& g/ P' u! o
* ?! O( l6 z6 e1 s4 Z. z
- W k' v4 l! s4 t! l; W - 7 j9 s3 N( T/ y0 m* J
3 b( U' W# i3 R9 ?%法二:方差比C检验! ^3 m% k8 z* p3 ^- D' Y; n8 c0 R
- ( I1 t. Q- g' x
: c. o" E$ @, @
disp('方差比C检验: ');
: m, X- f+ a5 ~4 k5 ]+ ` - 9 h8 V/ h7 m7 |' Q& ]6 u( Y! i
) R# B5 C1 B" a, m, S5 uC = std(E, 1) / std(X0, 1)
7 y+ X( u* `" C' [ y/ k+ ~8 i - . u8 }6 b6 P, t, b% A
" _9 H' f" f, ?' N/ C* g6 L& a2 L Y3 I" W4 }) j) O6 P$ @
- % O8 p2 b+ t- d. e
, m$ n" m2 A) L, q* f7 ^%小误差概率P检验
]( G* g8 A$ U$ L. {: H
h" E' X5 J; g: E+ K5 F2 m$ _- v% r3 v0 \( e: a# \
S1 = std(X0, 1);
2 m7 B" D# d' @6 v) T6 e- 6 V) {/ o; \ O+ _# B/ q) o, l
3 H9 a8 f* N- vtmp = find(abs(E - mean(E)) < 0.6745 * S1);2 Z$ t0 S( v+ G# N* J6 m' B
- , w6 s+ l& m- G7 q4 Y" G
' l$ F- b( S$ [) C. v
disp('小误差概率P检验:');
: T/ ] [: [) Z; r* F4 E4 I - 9 i% B2 s, T* F9 L4 `' g; ~4 q6 ]
1 Q9 B1 V/ b5 s# t8 M5 tP = length(tmp) / n
4 w+ }. @6 v e. j2 e! d! `3 S - . T1 K- e# Z; |2 V: F+ r
" U; |# O( h/ @8 _/ w5 Q; ^6 D/ r
& F8 j/ I5 I" D: _' C
4 t) J8 ~; I$ E, C
- Q/ s; z& B, z* y+ v4 O%%绘制曲线图(根据不同的题目以下的代码会有所不同,故不贴出来,大家自己动手写吧)
& J( q- y. D6 ~ S9 J9 u, d
) s% {! z" L8 c* y. g
& A7 n: y. e- b& {7 `3 x
2 ` \+ b- v3 ?# A/ L; n
+ U, o# E" y v; w7 l
6 [! I; [% J3 f( q1 B
| 欢迎光临 数学建模社区-数学中国 (http://www.madio.net/) |
Powered by Discuz! X2.5 |