数学建模社区-数学中国
标题:
RBF神经网络简单介绍与MATLAB实现
[打印本页]
作者:
zhangtt123
时间:
2020-5-23 14:56
标题:
RBF神经网络简单介绍与MATLAB实现
RBF的直观介绍
! p/ K7 `) B. k6 ]$ Y) D
RBF具体原理,网络上很多文章一定讲得比我好,所以我也不费口舌了,这里只说一说对RBF网络的一些直观的认识
" T2 E1 ]; Y7 [; s6 r
9 p6 ~3 x: o- K
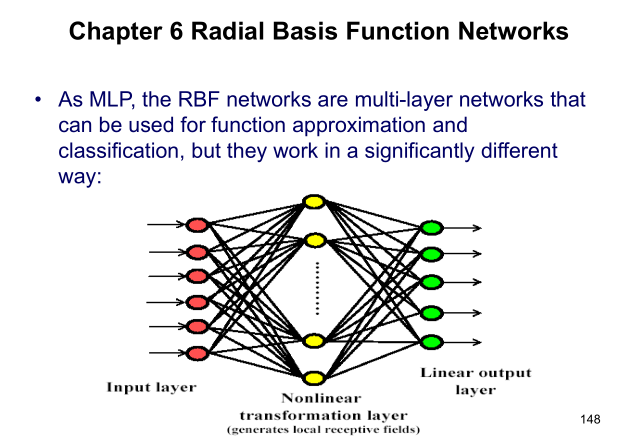
1 RBF是一种两层的网络
+ O0 E/ V" L8 D2 o0 \% ?! _6 s
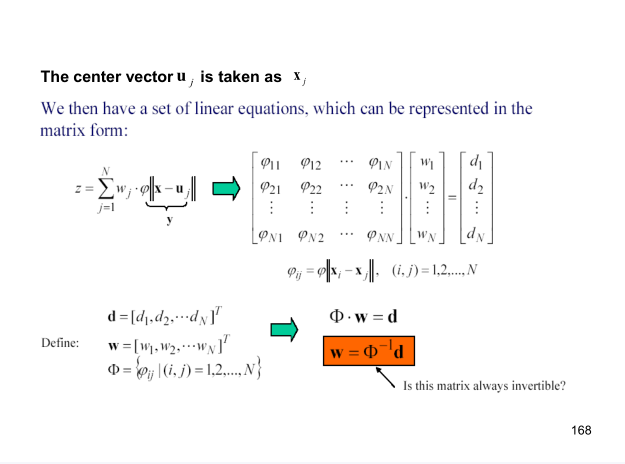
是的,RBF结构上并不复杂,只有两层:隐层和输出层。其模型可以数学表示为:
% c5 w5 s% g: m. t; w
yj=
i=1∑nwijϕ(∥x−
ui∥2),(j=
1,…,p)
" J3 G& r- f2 N
/ [3 s* q. V9 Y4 A5 Y& v& W
: J; E! ^) ?" _
2 RBF的隐层是一种非线性的映射
4 b% R: ^0 \$ Z$ I
RBF隐层常用激活函数是高斯函数:
! W3 q+ e2 b1 t& w, f# R: \
! j/ @9 B2 S% q9 }* y
ϕ(∥x−
u∥)=
e−σ2∥x−u∥2
$ l7 R% |$ m. ^+ Z
% z" K+ @* A% X+ R) B; `1 ?
2 b1 j* }1 ?$ t& r- x1 F+ n
; S( C# Q+ _ h# _2 g/ ^
3 RBF输出层是线性的
6 W9 o5 i/ A& j c
4 RBF的基本思想是:将数据转化到高维空间,使其在高维空间线性可分
( E4 Q* E+ F( \7 ^% }2 p$ F
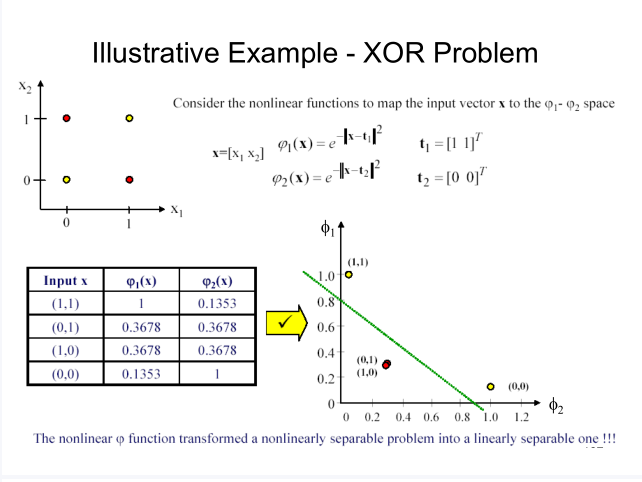
RBF隐层将数据转化到高维空间(一般是高维),认为存在某个高维空间能够使得数据在这个空间是线性可分的。因此啊,输出层是线性的。这和核方法的思想是一样一样的。下面举个老师PPT上的例子:
, Y- o8 O. a* u, m4 U. t
: g: ^; V3 b/ q7 ^
( |# H* X. t+ i
上面的例子,就将原来的数据,用高斯函数转换到了另一个二维空间中。在这个空间里,XOR问题得到解决。可以看到,转换的空间不一定是比原来高维的。
, F0 M: q- F7 J0 }
( D1 h0 _9 d. c' j: S
RBF学习算法
* [& I% ]2 b: O3 c% b
i2 D2 a/ n2 R. j' f
/ |2 Y4 A4 W6 x8 e
: C0 R$ _( ], i* B7 I4 `2 Z, v5 ~8 J
对于上图的RBF网络,其未知量有:
中心向量
ui
,
高斯函数中常数σ,
输出层权值
W。
0 p. V: R3 {: ?
学习算法的整个流程大致如下图:
' v) n; i% F% J- N$ x+ i# m7 D0 }
<span class="MathJax" id="MathJax-Element-5-Frame" tabindex="0" data-mathml="W W" role="presentation" style="box-sizing: border-box; outline: 0px; display: inline; line-height: normal; font-size: 19.36px; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; position: relative;">WW
/ `. P0 F$ {3 q5 [0 S- k
. E+ @8 k% |8 R1 |/ E+ Y9 A1 o+ L& D6 g
8 j% B% T0 M( Z: A
具体可以描述为:
+ d) l0 @5 j, f8 P* Z; u( O( b
1 [+ u9 l6 n4 M9 a& e1 m! Z
1.利用kmeans算法寻找中心向量
[color=rgba(0, 0, 0, 0.749019607843137)]
ui
1 x0 X, J; Y: |* N) [! {0 I" m
- Y( t) f; m, \8 D* T3 p y) l1 C
2.利用kNN(K nearest neighbor)rule 计算 σ[color=rgba(0, 0, 0, 0.75)]
4 s9 n& k. u; j& @' O
σ
5 J& C3 x# \; g6 ~
i=
K1k=1∑K∥uk−ui∥2
4 O4 a' e' Z3 q4 U; F5 t' h5 n
" C0 a3 ~, ]( @3 ?
9 }. {/ _: s6 L8 I5 {( y/ W0 S1 L3 ]
, L7 H8 b2 v( \, w, C
3. [color=rgba(0, 0, 0, 0.75)]
W
[color=rgba(0, 0, 0, 0.75)]
可以利用最小二乘法求得
# h: U1 }; k' v8 e* w# w) d6 p
* g% W* O4 O8 H
Lazy RBF
1 @0 W# t B u
" m1 q; b7 X- ~# N; L$ {/ U+ O
可以看到原来的RBF挺麻烦的,又是kmeans又是knn。后来就有人提出了lazy RBF,就是不用kmeans找中心向量了,将训练集的每一个数据都当成是中心向量。这样的话,核矩阵Φ就是一个方阵,并且只要保证训练中的数据是不同的,核矩阵Φ就是可逆的。这种方法确实lazy,缺点就是如果训练集很大,会导致核矩阵Φ也很大,并且要保证训练集个数要大于每个训练数据的维数。
) I" s( l* {: X$ u4 \- h9 f/ D, v8 L
. D) G! K- C" \4 e" z
MATLAB实现RBF神经网络
下面实现的RBF只有一个输出,供大家参考参考。对于多个输出,其实也很简单,就是WWW变成了多个,这里就不实现了。
0 ~/ l3 n8 g G! d: I
# i- x4 q; x" S% s- `8 d4 r' n, s
demo.m 对XOR数据进行了RBF的训练和预测,展现了整个流程。最后的几行代码是利用封装形式进行训练和预测。
- C9 b4 f6 u6 l/ ?- c
% X: d" }/ z6 `5 o( {' ^& k
clc;
; A9 k5 f5 i# G
clear all;
/ f# f n+ {0 J- y% x
close all;
& I/ s8 k* h% s1 v) ^, _7 {
' W$ M# z) A# K+ i
%% ---- Build a training set of a similar version of XOR
, Q5 W( v. }+ [- a2 T* `; k+ T% h
c_1 = [0 0];
w- O9 K4 t5 e$ l! T# }3 @0 |$ k
c_2 = [1 1];
Z6 J% J, R9 ^& J0 s6 O. y. m7 f" E
c_3 = [0 1];
' |" G; ? V* F' X, Z$ p( ?0 u
c_4 = [1 0];
% |& Z7 T1 b2 t* H/ ^3 f3 @
- c$ ]2 @$ ~3 N: ]; o5 @
n_L1 = 20; % number of label 1
4 K& d X# I7 J9 p6 a6 T
n_L2 = 20; % number of label 2
0 g5 N* p1 e& A6 t
, Q% d8 Z$ S5 s, X( u
# F& u# J& `1 k' h4 K( T
A = zeros(n_L1*2, 3);
& F9 K( a9 [; v# U4 l2 Q- j
A(:,3) = 1;
: p. w! d* R6 c4 A, r7 o9 ^- A
B = zeros(n_L2*2, 3);
; w/ }; N% r% @# r- Y+ {4 s
B(:,3) = 0;
! K: j0 S" J* p# u* u
2 S3 t, b" |4 i, _4 L7 w4 Y+ O
% create random points
. t3 U+ T5 B9 |+ `5 z
for i=1:n_L1
% t! o% `( }4 v/ x5 E2 c
A(i, 1:2) = c_1 + rand(1,2)/2;
, a& Z' X9 e/ v1 C3 i
A(i+n_L1, 1:2) = c_2 + rand(1,2)/2;
' k! c7 A$ ?3 |" [
end
; A$ p/ n: p: j; `. i2 \: ~& v" f& P
for i=1:n_L2
: l$ M( D8 d) W
B(i, 1:2) = c_3 + rand(1,2)/2;
; i7 k# o% P( [# b! q! R/ h' `
B(i+n_L2, 1:2) = c_4 + rand(1,2)/2;
7 f+ e' X* `) `' W. ^
end
+ J& m$ C( E1 c8 k/ P
: f( Z% E5 Q9 c4 L
% show points
) U" C+ ^. Z4 x3 ]5 c/ m4 C
scatter(A(:,1), A(:,2),[],'r');
9 y) d+ y, Q! t; D
hold on
, i3 q, B8 m4 z8 Z/ M5 @
scatter(B(:,1), B(:,2),[],'g');
# G; B0 ]/ \8 K4 L$ c
X = [A;B];
! U8 o& W% t9 S0 K d
data = X(:,1:2);
" z8 Z: V# S. Z- V" v) U
label = X(:,3);
9 S: Z1 \8 V& N# C# l
0 J X0 {2 C; k) T' N
%% Using kmeans to find cinter vector
% E( A% L1 P/ s! T& ?' r- q
n_center_vec = 10;
# {; m. F2 G- D2 j% s# Y- d
rng(1);
. S% V( L. K& i6 F; i+ B5 S% g
[idx, C] = kmeans(data, n_center_vec);
7 S7 @5 J3 K' D4 A5 J
hold on
! O( V9 s4 @& V. X
scatter(C(:,1), C(:,2), 'b', 'LineWidth', 2);
4 e2 K( y& t9 b7 q' z
2 k3 P; g$ m. z' n1 J" j3 W
%% Calulate sigma
2 y' N; l- P" i7 k* H( y y# C5 j
n_data = size(X,1);
0 a. U3 J* o9 s6 [: t% O
( p. g7 g; p9 Y5 q7 W$ T6 x; b
% calculate K
7 s# O6 m3 g7 \' e/ H4 o
K = zeros(n_center_vec, 1);
4 T7 W( S7 H8 }& ?
for i=1:n_center_vec
9 F: |8 K& I" {/ p4 q& T
K(i) = numel(find(idx == i));
) U! v! `% ~7 H% s. H
end
% d# P3 Z4 [3 [7 W6 q3 T O
- O! I/ \" l% m% X7 b
% Using knnsearch to find K nearest neighbor points for each center vector
x# P" q. Q3 o' N. O5 I: W' Q
% then calucate sigma
9 b; f4 l6 [1 Z
sigma = zeros(n_center_vec, 1);
5 `$ i- I9 \# C5 b1 n6 m" v
for i=1:n_center_vec
: Y2 c4 X) j4 e
[n, d] = knnsearch(data, C(i,:), 'k', K(i));
, C' d; A# F+ |( @* l
L2 = (bsxfun(@minus, data(n,:), C(i,:)).^2);
4 M7 U n. b( \9 K
L2 = sum(L2(:));
/ Q, F7 s9 r- ]) L: J3 k# _
sigma(i) = sqrt(1/K(i)*L2);
* s" S8 v( v5 R
end
: R: K' a5 r) @6 U8 C1 S- a: b
% r; C. a9 s# M; q& Q) p1 l
%% Calutate weights
3 H4 P6 Q: K' C
% kernel matrix
7 z; x+ s2 l S9 E
k_mat = zeros(n_data, n_center_vec);
" @! g& o e- w6 `
: n3 x. g8 B; L# f
for i=1:n_center_vec
: i8 L. I3 R) _3 R
r = bsxfun(@minus, data, C(i,:)).^2;
; o6 y+ w: t* L+ k9 {! t
r = sum(r,2);
7 W; T/ S" M" s4 E$ U( u
k_mat(:,i) = exp((-r.^2)/(2*sigma(i)^2));
2 `$ O9 }! ?7 `# v# d0 s" l
end
, y# `- {! ]. z7 N4 C/ _6 I9 s) K
' g2 W Z5 E6 _9 b+ o0 \$ r3 k9 P- i
W = pinv(k_mat'*k_mat)*k_mat'*label;
- ^3 u/ T/ \ v- [* H% J8 B
y = k_mat*W;
' X5 E4 L3 @9 D5 r. Z/ C% Y
%y(y>=0.5) = 1;
. C1 a ]( A3 _1 l& z9 U
%y(y<0.5) = 0;
+ b* e5 X( K/ K: {+ S; v/ p
# f8 r' v8 ]. n' |0 ?# y3 _! I
%% training function and predict function
. k% n) y6 {& t. b4 C( F" L
[W1, sigma1, C1] = RBF_training(data, label, 10);
{3 n8 p/ \" I, ~) B; K
y1 = RBF_predict(data, W, sigma, C1);
1 g/ \2 f& C# X: `* W3 P
[W2, sigma2, C2] = lazyRBF_training(data, label, 2);
/ f% v- Y: Z! |
y2 = RBF_predict(data, W2, sigma2, C2);
$ U5 A2 X3 @7 F# L2 g7 ~
' s: n2 V0 E( ?. G
% l& `5 l% V& ]! B2 G- _; h' y
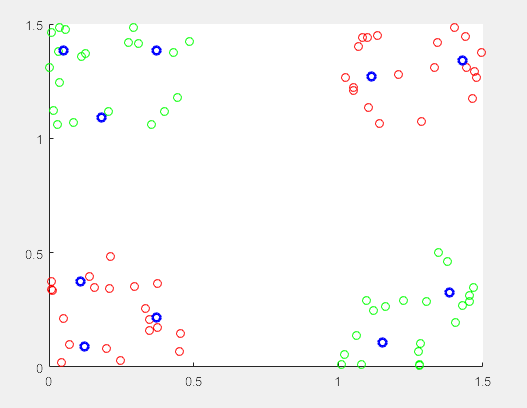
上图是XOR训练集。其中蓝色的kmenas选取的中心向量。中心向量要取多少个呢?这也是玄学问题,总之不要太少就行,代码中取了10个,但是从结果yyy来看,其实对于XOR问题来说,4个就可以了。
2 f9 }% _3 Q9 C( P) W' @
5 ?9 F% m; e' ]" O, g
RBF_training.m 对demo.m中训练的过程进行封装
8 Q' G; n+ y( R D- Q. F
function [ W, sigma, C ] = RBF_training( data, label, n_center_vec )
/ o& C$ t5 j" k( _5 s$ w" t
%RBF_TRAINING Summary of this function goes here
3 @0 O, u& J) T5 Z
% Detailed explanation goes here
: G6 t. [1 G. A& {. K! @
+ k; Z6 y( [# b& H
% Using kmeans to find cinter vector
$ `) u; o: q+ D# Z: w* G& `& t# L
rng(1);
" B# C* E# d" {$ A
[idx, C] = kmeans(data, n_center_vec);
/ _5 M: M7 `& D/ @, H* t! g
: X2 s* n* _" r' }+ f' e: \+ |
% Calulate sigma
0 u( T; Z# _6 R* _) u( i& U! A
n_data = size(data,1);
: a* D; L2 u) P$ o% e1 s& L1 D
% E" N% `6 H m* Y* p4 \
% calculate K
* {. ]# {: G$ e! E# |3 \
K = zeros(n_center_vec, 1);
& X @; D/ |. V( @ ]9 G, f
for i=1:n_center_vec
# V# N0 I/ @1 N! R8 ^0 C1 p
K(i) = numel(find(idx == i));
+ M# X! I5 R5 V/ x4 ?
end
Q' o* `% X4 u1 @
, p# ?" t/ h6 f4 o- M3 G! I
% Using knnsearch to find K nearest neighbor points for each center vector
: n; W* m i% _0 j" b6 T L% u
% then calucate sigma
7 y8 n2 S; n% m! E0 J0 s
sigma = zeros(n_center_vec, 1);
8 t) q$ c3 U+ f' C( D/ H; n
for i=1:n_center_vec
' B9 H/ Z* S% }5 C. m# Y
[n] = knnsearch(data, C(i,:), 'k', K(i));
1 g, h9 S0 z4 _! B' q! x
L2 = (bsxfun(@minus, data(n,:), C(i,:)).^2);
6 a9 s$ a; N" |$ L8 b, o$ ] R2 u
L2 = sum(L2(:));
% [5 f" M: L c1 Z2 z1 Q2 ]9 ?) s4 V
sigma(i) = sqrt(1/K(i)*L2);
& J6 ^2 T, p r+ I' `- H7 \; y( h. @
end
, p( Z* Z& y* P" _* i% y
% Calutate weights
. I5 _" w" z% f
% kernel matrix
b0 K G: s# W+ X5 S: C$ Z
k_mat = zeros(n_data, n_center_vec);
; i' H, q4 S2 E1 k$ W) }
! E! d3 A1 y) C5 g% q9 d0 V
for i=1:n_center_vec
: _* l7 r" X9 k0 L
r = bsxfun(@minus, data, C(i,:)).^2;
% C) y: p7 @' e. l4 ]3 Q: T
r = sum(r,2);
: V& Q1 f* R W$ Z* x; t/ q
k_mat(:,i) = exp((-r.^2)/(2*sigma(i)^2));
5 f/ D' x+ N+ i3 W( ?
end
* g- a9 l0 ]: m; j- B
. Q: B. J( U( {2 x* q6 f4 K2 |; Y
W = pinv(k_mat'*k_mat)*k_mat'*label;
* V1 S" P% P) e( I$ E" j2 j
end
' {* k, ?6 v% T) I p1 C
) U0 P) q8 _8 l
RBF_lazytraning.m 对lazy RBF的实现,主要就是中心向量为训练集自己,然后再构造核矩阵。由于Φ一定可逆,所以在求逆时,可以使用快速的'/'方法
7 g) z# B; g2 e# k* }8 M j0 ]
( F y/ S+ Y4 L! D. ?% X, I
function [ W, sigma, C ] = lazyRBF_training( data, label, sigma )
. k! x3 u# X% f4 B
%LAZERBF_TRAINING Summary of this function goes here
" w: F; i. Y% X+ R7 u/ P
% Detailed explanation goes here
" _# T7 S8 ~1 v1 N. x6 r
if nargin < 3
# n6 T" H" P, ?$ l! m8 C
sigma = 1;
2 J X3 Q& ]$ m) ~
end
/ n0 U3 Y' d' f4 v
' y# r* I$ q4 A2 P% G
n_data = size(data,1);
7 _1 l, S/ y1 U8 k/ X V
C = data;
1 k, T* n: ^- U, a' d% V
. M4 ? F4 @- y
% make kernel matrix
" o% P! x$ e& ?& o9 \) `9 O8 |2 R
k_mat = zeros(n_data);
) l2 L/ Z1 w0 x8 L* W+ v3 y+ F: |
for i=1:n_data
" j/ j" r- M" j; N" \+ ?
L2 = sum((data - repmat(data(i,:), n_data, 1)).^2, 2);
" ~0 J6 ^; _3 H2 h, K
k_mat(i,:) = exp(L2'/(2*sigma));
5 o2 H6 ?! x2 I
end
6 y8 ~& \: b6 D- s/ {
5 _0 ^; R6 R4 U; ?6 D! J
W = k_mat\label;
' ~; `7 u9 Z" U. U G* \ Q
end
9 @/ |& b' |: K6 I: q2 e6 v
. G3 S5 W4 u; x# I' I3 a% J! w
RBF_predict.m 预测
& W9 S& ]; Q: z( B: A
6 T. H' }6 y: o- z8 l/ `4 A
function [ y ] = RBF_predict( data, W, sigma, C )
" H$ y% m5 N G U6 Y
%RBF_PREDICT Summary of this function goes here
8 ? l& C" E5 w' h
% Detailed explanation goes here
3 I( A/ @0 H' h, Q
n_data = size(data, 1);
?, \. E% [/ V
n_center_vec = size(C, 1);
, E/ q: D% n( Q1 N* B5 p
if numel(sigma) == 1
8 L1 I1 t3 B* T7 K
sigma = repmat(sigma, n_center_vec, 1);
3 K, u) k! G! K0 p0 u$ g o
end
. [! }+ x* X/ Q0 K) q
% `4 a6 j0 b0 c
% kernel matrix
0 ]' V( N* S' j3 L) T4 W
k_mat = zeros(n_data, n_center_vec);
8 ]" W1 V5 a& w% T9 }
for i=1:n_center_vec
4 X- o2 ^6 D1 M0 d
r = bsxfun(@minus, data, C(i,:)).^2;
7 [' h( ]6 k% P% Q) r
r = sum(r,2);
7 C) L$ @, ]) O- \/ n% i
k_mat(:,i) = exp((-r.^2)/(2*sigma(i)^2));
, @( P* n% f7 c! `
end
- F' h. i4 u$ h# X
4 f1 z P5 h6 w* x& x4 | p M( L, p
y = k_mat*W;
|9 r: S. p! K. D0 k/ I
end
7 Z4 Z0 T9 W6 a" u# d$ F
# o3 e4 ?8 O" F' r
————————————————
% p! ?0 F; v2 f6 P- n
版权声明:本文为CSDN博主「芥末的无奈」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
# z1 n W: d- F G# c2 Q
原文链接:https://blog.csdn.net/weiwei9363/article/details/72808496
& C! Y: y1 D2 L$ @3 v, I
/ R2 Q* e$ ?) h! M& l; @: U; J$ y
/ U, U8 m* o6 f: z( @
# x6 J1 V8 u0 i# w
欢迎光临 数学建模社区-数学中国 (http://www.madio.net/)
Powered by Discuz! X2.5
 / [3 s* q. V9 Y4 A5 Y& v& W
/ [3 s* q. V9 Y4 A5 Y& v& W
 : g: ^; V3 b/ q7 ^
: g: ^; V3 b/ q7 ^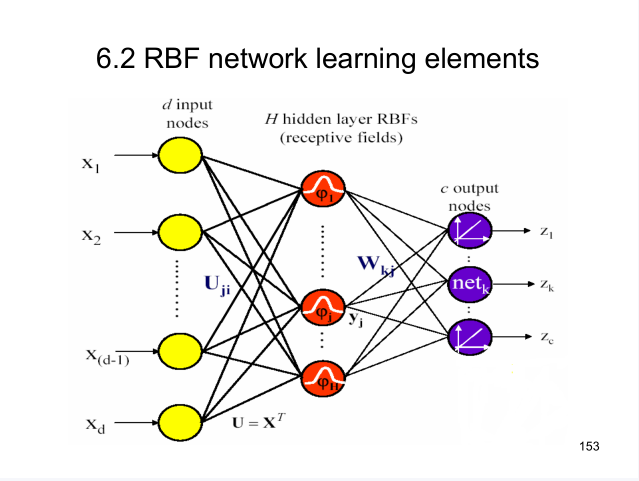 i2 D2 a/ n2 R. j' f
i2 D2 a/ n2 R. j' f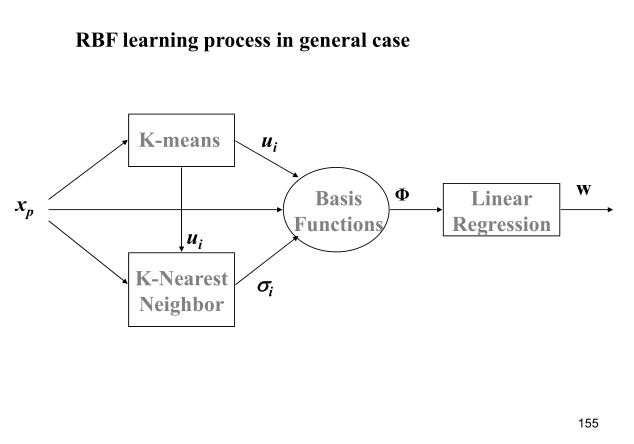
 ' s: n2 V0 E( ?. G
' s: n2 V0 E( ?. G