
 解决方案LQR
解决方案LQR 注意,其中C矩阵是根据实际控制需求人为设定的,F是已知的。
注意,其中C矩阵是根据实际控制需求人为设定的,F是已知的。 LQR算法流程如下:
LQR算法流程如下:
 iLQR这里iLQR中的“迭代”不是动态规划中的迭代,倒是和牛顿法里面的迭代过程非常相似,我们知道梯度下降是利用泰勒展开的一阶项去近似原函数迭代求下一个值,而牛顿迭代是利用二阶项去近似原函数,模型更准确,收敛更快。和iLQR有什么关系呢?先来看一下如何应对非线性。它将非线性的环境和cost函数,通过泰勒展开局部线性化,之后通过LQR的barkward过程解出线性化环境、cost下的“最优解”。但是,这得到的“最优解”并不是我们想要的最优轨迹,因为类似于牛顿迭代,LQR backward整个过程的等同于求导,只是对此时x0处展开的函数求极值(红色下划线部分),而该部分与和原函数是有误差的,得到的新坐标x也与只能通过一步步迭代逼近最优解。
iLQR这里iLQR中的“迭代”不是动态规划中的迭代,倒是和牛顿法里面的迭代过程非常相似,我们知道梯度下降是利用泰勒展开的一阶项去近似原函数迭代求下一个值,而牛顿迭代是利用二阶项去近似原函数,模型更准确,收敛更快。和iLQR有什么关系呢?先来看一下如何应对非线性。它将非线性的环境和cost函数,通过泰勒展开局部线性化,之后通过LQR的barkward过程解出线性化环境、cost下的“最优解”。但是,这得到的“最优解”并不是我们想要的最优轨迹,因为类似于牛顿迭代,LQR backward整个过程的等同于求导,只是对此时x0处展开的函数求极值(红色下划线部分),而该部分与和原函数是有误差的,得到的新坐标x也与只能通过一步步迭代逼近最优解。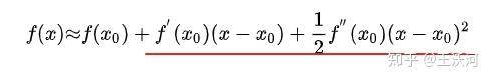 二阶泰勒展开忽略高阶项
二阶泰勒展开忽略高阶项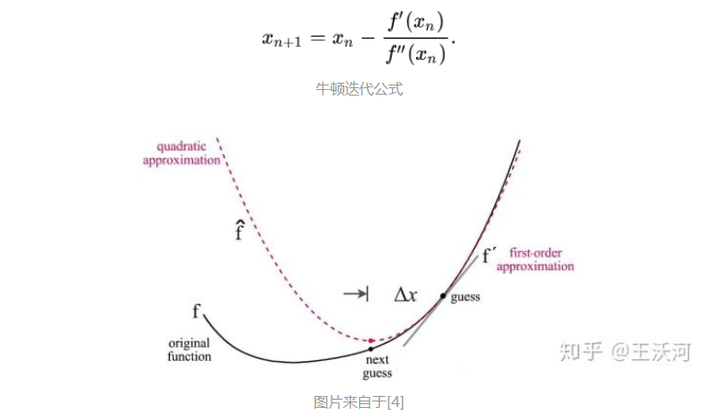 图片来自于[4]
图片来自于[4]

 iLQR的改进文献[1]对以上iLQR算法作出几点改进,伯克利的Guided Policy Search[2]中也采用该方法来作为强化学习的引导策略。
iLQR的改进文献[1]对以上iLQR算法作出几点改进,伯克利的Guided Policy Search[2]中也采用该方法来作为强化学习的引导策略。| 欢迎光临 数学建模社区-数学中国 (http://www.madio.net/) | Powered by Discuz! X2.5 |