数学建模社区-数学中国
标题:
投资组合问题
[打印本页]
作者:
浅夏110
时间:
2020-6-16 10:14
标题:
投资组合问题
基本的投资组合模型
7 V/ B& w1 D% y+ n; F. I+ N0 v, j- e: H
例5 美国某三种股票( A ,B , C)12年(1943-1954)的价格(已经包括了分红在内)每年的增长情况如表6所示(表中还给出了相应年份的500种股票的价格指数 的增长情况)。例如,表中第一个数据1.300的含义是股票 A在1943年的年末价值是 其年初价值的1.300倍,即收益为30%,其余数据的含义依此类推。假设你在1955年 时有一笔资金准备投资这三种股票,并期望年收益率至少达到15%,那么你应当如何 投资?当期望的年收益率变化时,投资组合和相应的风险如何变化?
- x3 J# P8 f. {: p! j2 }
' `: T+ f: C2 I9 K( h3 p9 V/ S) l
8 w) `( v1 W. K0 p* O7 Y
6 ~4 C$ H- b6 B5 {4 n8 r- [' W7 x4 H
2 W1 L/ w/ W7 Q
6 ~- x6 R1 u: `% U% f6 h
(1)问题分析
1 m, P7 B; m& ^; Z- [- H$ U5 ^( C/ G
- j" k7 _: @& h0 U4 i+ Z
本例的问题称为投资组合(portfolio)问题,早在1952年Markowitz就给出了这个模型的基本框架,而且这个模型后来又得到了不断的研究和改进。一般来说,人 们投资股票时的收益是不确定的,因此是一个随机变量,所以除了考虑收益的期望值外, 还应当考虑风险。风险用什么衡量?Markowitz建议,风险可以用收益的方差(或标 准差)来进行衡量:方差越大,则认为风险越大;方差越小,则认为风险越小。在一定 的假设下,用收益的方差(或标准差)来衡量风险确实是合适的。为此,我们先对表6 中给出的数据计算出三种股票收益的均值和方差(包括协方差)备用。
" G' o8 q! d3 y! h& F
0 _ N( y; A) u" R' E+ f2 }& U2 i
一种股票收益的均值衡量的是这种股票的平均收益状况,而收益的方差衡量的是这 种股票收益的波动幅度,方差越大则波动越大(收益越不稳定)。两种股票收益的协方 差表示的则是它们之间的相关程度:
* M/ U, T7 z$ `2 r, v
5 A1 |) ^+ u' s3 J. j9 }
i)协方差为0时两者不相关。
2 F9 i8 ]0 o2 k: f0 d4 i% g4 h
3 ?- _6 y$ T1 Q" U6 F
ii)协方差为正数表示两者正相关,协方差越大则正相关性越强(越有可能一赚 皆赚,一赔俱赔)。
6 Y! ]8 F/ J3 [8 p+ s7 H& a( k
, i+ n1 O K1 z, R$ f5 }6 v& i: S
iii)协方差为负数表示两者负相关,绝对值越大则负相关性越强(越有可能一个 赚,另一个赔)。
) z, |: a( F5 C2 n. s
4 l8 z2 x7 b: j* d
记股票 A , B,C 每年的收益率分别为 (注意表中的数据减去1以后才是年收益率),则
是一个随机变量。用E 和D分别表示随机变量的数学期望和方差算子,用cov表示两个随机变量的协方差(covariance),根据概率论的知 识和表6给出的数据,则可以计算出年收益率的数学期望为
& R* P5 s- B. O) n1 \
: P# Y* w" [% A$ w' @) i
= 0.0890833, = 0.2136667, = 0.2345833 (1)
5 d& G8 C) G! m: B
( Y+ ]4 E( \1 u+ S
同样,可以计算股票 A ,B ,C年收益率的协方差矩阵为
! u3 {! G: p5 m9 H: s
r! G9 }5 [3 }: y5 [, c/ `( V' u
+ @1 N7 s+ n q2 ? C7 B
6 }( v I, V/ h( H" g
计算的LINGO程序如下:
, W5 d: f. q5 {! x9 G1 _6 X
- I3 j5 r7 X; n% Y. J' f
MODEL:
1 Z# o& n( A0 z5 ~
Title 均值向量Mean与协方差矩阵COV;
& ~" m6 ^. C5 L1 y/ T
SETS:
# @+ J) W: \/ s, q2 N
YEAR/1..12/;
2 n' Z' I* k# }% ]2 ^9 y, R8 r
STOCKS/ A, B, C/: Mean;
# O' t J' |% Y6 ^
link(YEAR, STOCKS): R;
# F, e2 z, z6 o* J/ ?8 R
temp/1..5/;
( U+ e, M- Z4 Z& S
tmatrix(YEAR,temp):tm;
* t# m6 h. ~: l* x! K
STST(Stocks,stocks): COV;
O6 l" P% @* R' V# l7 |# M
ENDSETS
) C& a" W% t4 l2 W7 Y) f2 ~% }# y
DATA:
# X; X3 D% S0 v @# H& r
tm =
/ y$ X% S7 F# }4 b j0 _1 c; A" D
1943 1.300 1.225 1.149 1.258997
6 k4 j, I6 U5 X3 C5 @. O) e) _
1944 1.103 1.290 1.260 1.197526
$ k5 K0 G+ }* U9 u" Z7 q8 x
1945 1.216 1.216 1.419 1.364361
# S! K$ A) J# }+ F% g& w
1946 0.954 0.728 0.922 0.919287
6 z6 U( }3 S [; _
1947 0.929 1.144 1.169 1.057080
- T) A) l0 `1 t! X/ ]
1948 1.056 1.107 0.965 1.055012
8 o& A7 w U0 a( f" z6 b, K
1949 1.038 1.321 1.133 1.187925
- h( p$ a f9 s
1950 1.089 1.305 1.732 1.317130
# _$ Z2 s4 Z/ P' b1 j
1951 1.090 1.195 1.021 1.240164
* t" J1 B7 i( c, W4 Y
1952 1.083 1.390 1.131 1.183675
3 R U) d. N8 M. I
1953 1.035 0.928 1.006 0.990108
# Y) Y% I3 i: n0 [. X. M4 M
1954 1.176 1.715 1.908 1.526236;
1 W/ k+ F4 l3 E) d2 ~
@text(data1.txt)=R;
: F; [+ B B# x: |# N- o
@text(data2.txt)=Mean;
) [7 `- k/ ?& |5 K4 C
@text(data3.txt)=COV;
6 T. [1 p: @% r3 j
ENDDATA
1 r8 y0 K0 c3 q. R9 U6 C8 L, p1 B/ H
CALC: !计算均值向量Mean与协方差矩阵COV;
/ t% d: m; S c% W8 B p: o1 B1 i
@for(tmatrix(i,j)|j #ge#2 #and# j #le# 4:R(i,j-1)=tm(i,j)-1);
2 n- S8 a0 e- ?! V( v
@for(stocks(i): Mean(i) = @sum(year(j): R(j,i)) / @size(year) );
2 \7 R. }" }( w3 b+ L( V2 L4 T
@for(stst(i,j): COV(i,j) = @sum(year(k): (R(k,i)-mean(i))*(R(k,j)-mean(j))) / (@size(year)-1) );
! A0 R: v H# C) ~3 l. c
ENDCALC
" g7 e8 f7 d/ ]" }1 a8 G2 L
END
) q9 ^$ u* ^5 m7 b# @7 W
注意模型中计算协方差矩阵COV时,分母是样本数减去1,而不是样本数,这是常 用的计算方法,主要是为了保持这个估计的无偏性(当然,样本数较大时两者差别不太)。
8 o2 B% |# v2 \
(2)模型建立
3 x# @) | W+ I6 ~4 c# v
用决策变量 分别表示投资人投资股票 A ,B , C 的比例。假设市场上没有其它投资渠道,且手上资金(可以不妨假设只有1个单位的资金)必须全部用于投资这 三种股票,则
8 n- V' N$ g& S# }' _& h
5 q! Z. G' P" ]2 R7 i L- ~8 [
( 2 )
9 p& G+ I. ]1 l! s3 @$ Q6 o* L
; C6 i: M) \: z; s# s
年投资收益率
也是一个随机变量。根据概率论的知识,投
; p; ?+ Y6 A6 G# j
资的总期望收益为
( 3 )
7 @9 V" w6 l/ o; u) G" n
7 P$ r8 S- n+ ]# K
( 4 )
" _0 ~/ V& i5 n0 ^' ^
1 p2 C0 f8 G! T
实际的投资者可能面临许多约束条件,这里只考虑题中要求的年收益率(的数学期 望)不低于15%,即
: u1 C# i8 w, t* Y" R9 f
2 ]6 t: |. l2 u
( 5 )
5 m. o9 m9 R% ?$ a/ ], } q" k
" y# O5 V7 {7 O3 n" }
所以,最后的优化模型就是在约束(2)和(5)下极小化(4)。由于目标函数V 是决策变量的二次函数,而约束都是线性函数,所以这是一个二次规划问题。
e4 o8 X% ]/ W9 K$ M8 V m
3 X2 \' E2 B8 E
(3)用LINGO求解模型
7 A* @! S$ n! j8 ?- k; B
# r2 G: N' T# y9 A5 Q6 K
编写LINGO程序如下
( u a/ I6 [, L* z/ } P- M
4 ^. }. S8 Z; F( W2 b' F- U( P6 [3 g
MODEL:
4 u$ r [) i+ _- j
SETS:
' ]% z5 H9 ]: Y3 U7 x% k
YEAR/1..12/;
( }, }' L# s$ l+ e4 h7 K
STOCKS/ A, B, C/: Mean,X;
0 K8 C N+ `* x J$ N
link(YEAR, STOCKS): R;
$ x3 `' I& [0 J
STST(Stocks,stocks): COV;
5 n' [4 w$ p9 |; S
ENDSETS
( l: F4 G. u; z( V
DATA:
' F. w: r5 P7 Q. D# S! S
TARGET=0.15;
! n; i R% n' U% I
Mean=@file(data2.txt);
, S# h/ q& l; T3 ~9 J. |
COV=@file(data3.txt);
' o, s3 |; J {1 n* m3 J ~! d
ENDDATA
0 n( }! Z9 `: i( o+ z+ e
[OBJ] MIN = @sum(STST(i,j): COV(i,j)*x(i)*x(j));
2 Q/ ^9 }9 i% l" X/ w
[ONE] @SUM(STOCKS: X) = 1;
! ~5 I* ]% W- s
[TWO] @SUM(stocks: mean*x) >= TARGET;
2 k" w* H! r) r- Y, E* G
END
7 x' L( @, O- u8 z6 s6 d
求得投资三种股票的比例大致是: A占53%,B 占36%,C 占11%。风险(方 差)为0.02241378。
9 V7 x* \* ]! ~5 K5 n" w
$ M9 [* Q, ?2 @+ G* J! r
(4)用MATLAB软件对模型进行参数分析
* Z0 J( b$ P7 Z8 \7 K5 O. ~
" i! v* X2 V: Y6 ]
对实际投资人来说,可能不仅希望知道指定的期望投资回报率下的风险(回报率的方差),可能更希望知道风险随着不同的投资回报率是如何变化的,然后作出后的投 资决策。这当然可以通过在上面的模型中不断修改约束中的参数(目前为0.15)来实 现,如将0.15改为0.2345,则表示投资回报率希望达到23.45%(这几乎是可能达到的最大值了,因为这几乎是三种股票中最大的投资回报率,即股票C 的回报率)。可 以想到,这时应主要投资在股票C 上。实际求解一下,可以知道最优解中投资股票C 的 份额大约是99.6%(剩余的大约0.4%投资在股票B 上)。 目前LINGO软件还没有二次规划灵敏度分析的功能。下面我们利用MATLAB软件进 行灵敏度分析,回报率的取值区间为[0.09,0.234],变化步长为0.002。
/ S' ], B/ m9 J5 ?; l/ l' R( `3 m
% |. @/ o- V7 H1 e8 K- H' m
编写程序 如下:
5 U5 u8 j% D* e! j" J
2 f. h" W5 q* E5 E) p
clc,clear
3 _: V3 e9 I I6 r: b3 a4 w; z4 q% r
load data2.txt,load data3.txt
" V0 i+ H9 t, x1 X- w. p0 D# I* d
h=reshape(data3,[3,3]);
# M4 y5 R3 V- n* q
a=data2';
5 h8 F. V) O) ^, q$ ^+ ~
solution=[];
4 o. Q$ _+ d9 Z- w4 p
target=0.09;
D6 F& o3 @" k. j' b5 V9 B7 m# _
hold on
' |: X- l( G: g, U: U
while target<0.234
' z- i L3 A% C) l8 h2 C( Z" M
[x,y]=quadprog(2*h,[],-a,-target,ones(1,3),1,zeros(3,1));
# c! z4 o( x) K% @! C7 X8 g
plot(target,y,'*b');
! Q& Y$ G- G; y+ z! t$ X+ H! I
solution=[solution [target;x;y]];
# U! @' a2 q6 f& t0 z3 a+ o
target=target+0.002;
/ z+ J9 M7 a( E
end
- q# @5 g- b7 [3 K
solution
0 t! w! b: G' y0 E# ~
得到的投资回报率与风险之间的关系曲线如图3所示 。
. M$ O1 M' P( \5 U3 k
' m( R, G8 a d) k4 b" {. w
& i, H8 L) P" L* l7 u2 I9 s" X
& |( w& @; ` D) W8 @" M9 _; r
从图3可以看出,投资回报率从22%附近开始,风险迅速增大。
) Y- K! d% z# i) w6 t1 f" C
/ p9 _* h' s1 }6 @; Z# k
8 H% I. V. u: l) X& Q# ]2 q+ O- a, [
2 y4 i- V/ y$ i& N2 y- E
存在无风险资产时的投资组合模型
% d+ G2 o# T7 N/ `$ J7 b
例6 假设除了例5中的三种股票外,投资人还有一种无风险的投资方式,如购买国库券。假设国 库券的年收益率为5%,如何考虑例5中的问题?
' a3 |, i5 o& _3 `) A
0 E* `0 d4 b# q# ]/ F
(1)问题分析
& O6 S7 w0 ?: @: w
6 V% G% k1 r' i% B: g- v6 c
其实,无风险的投资方式(如国库券、银行存款等)是有风险的投资方式(如股票)的一种特例, 所以这就意味着例5中的模型仍然是适用的。只不过无风险的投资方式的收益是固定的,所以方差(包 括它与其它投资方式的收益的协方差)都是0。
! M0 B+ g/ \+ d' `
# \: A. }3 F; b
(2)问题求解
& ?; N9 v- u# O; ]6 I
2 E1 q- P3 }# S2 v% U% J% Z
假设国库券的投资方式记为D,则当希望回报率为15%时,对应的LINGO模型如下:
3 M% B: c% m, M8 @$ [5 p; B* r, S
6 Q- J# Y0 p3 n3 L8 B
MODEL:
% G2 [4 J$ B' h1 T1 m
Title 含有国库券的投资组合模型;
5 J) R F* ]& g* k6 }% @
SETS:
2 I4 ^5 P( c0 M! B+ u' `. c+ [# L+ i
STOCKS1/ A, B, C/: mean1;
( y7 f8 S% K# [* w( ]" V2 K4 p
STST1(Stocks1,stocks1): COV1;
4 p( v) p8 p2 o- B9 O: G0 j
STOCKS/ A, B, C, D/: mean,X;
7 a6 |' C+ B6 H2 v0 V
STST(Stocks,stocks): COV;
) A+ J% u6 g- H3 H
ENDSETS
2 L. O: t; Y9 V8 {$ A
DATA:
! B9 a- S: x! A' B4 P
mean=0.05;
9 a- A7 V$ I: Z& ?& j2 u2 B
COV=0;
) A# t4 Y# h. ^; M+ o9 y {- W) X
COV1=@file(data3.txt);
1 P. k; `# r$ B# X$ G. ^: G4 G3 J
Mean1=@file(data2.txt);
: G( ~: s, |% }. V0 b
TARGET = 0.15; ! 0.10;
3 O; {& F6 t$ v& q& s
ENDDATA
* h7 F0 ^; r% [1 m9 O
calc:
, C6 F# Z% G# s3 U9 B
@for(STOCKS(i)|i #ne# 4: mean(i)=mean1(i));
0 d; D7 }' ~$ D8 K" _
@for(STST(i,j)| i #ne# 4 #and# j #ne# 4:COV(i,j)=COV1(i,j));
) K+ j j1 ~7 I- L% {7 N6 n
endcalc
9 ?6 S4 f* }7 F z7 E
[OBJ] MIN = @sum(STST(i,j): COV(i,j)*x(i)*x(j));
9 h, K3 e; o6 O4 I4 M' @
[ONE] @SUM(STOCKS: X) = 1;
\ A, W4 F5 |& z, ^
[TWO] @SUM(stocks: mean*x) >= TARGET;
/ B! ?# l. b( r1 G
END
! D5 ?6 o3 q. ~3 E) ^- k7 E
计算结果为,投资 A占8.7%,B 占42.9%,C 占14.3%, D (国库券)占34.1%,风险 (方差)为0.02080347。与例5中的风险(方差为0.02241378)比较,无风险资产的存 在可以使得投资风险减少。虽然国库券的收益率只有5%,比希望得到的收益率15%小很多, 但在国库券上的投资要占到34.1%,其原因就是为了减少风险。
' `3 D* Y6 e: e+ z+ z
' o1 L) o" { \3 u- k# t2 a' @5 w
现在,我们把上面模型中的期望收益减少到10%,即把数据段中的语句“TARGET = 0.15”改为“TARGET = 0.10”,重新求解模型。计算结果如下:
% E; k* b& L: ^3 m
) h& y3 E) w8 ^$ Q* x' O
投资 A占4.3%,B 占21.4%,C 占7.2%, D (国库券)占67.1%,此时风险(方差为 0.0052)进一步下降。请特别注意:你能发现这个结果(这里不妨称为结果2)与刚才 “TARGET = 0.15”的结果(这里不妨称为结果1)有什么联系吗? 仔细观察这两个结果,可以发现:结果2中投资在有风险资产(股票 A ,B , C)上的比例大约都是结果1中相应的比例的一半。也就是说,无论你的期望收益和风险偏好如何,你 手上所持有的风险资产本身相互之间的比例居然是不变的!变化的只是投资于风险资产与 无风险资产之间的比例。有趣的是,这一现象在一般情况下也是成立的,一般称为“分离 定理”,即风险资产之间的投资比例与期望收益和风险偏好无关。1981年诺贝尔经济学奖 得主Tobin教授之所以获奖,很大一部分原因就是因为他发现了这个重要的规律。 也正是由于有这样一个重要结果,我们在下面各节的讨论中就不再考虑存在无风险资产 的情形了,而只考虑确定风险资产之间的投资比例。
+ l n+ q {+ B$ h0 \6 ]: A
8 L" @# d5 U9 e- l0 X
6 E/ F( N" F! x* A% O8 d7 [
5 H8 C. E2 n/ B/ b
考虑交易成本的投资组合模型
5 Y. V$ Z( k6 S& S" E+ r
例7 继续考虑例5(期望收益仍定为15%)。假设你目前持有的股票比例为:股票 A占 50%,B 占35%,C 占15%。这个比例与例5中得到的优解有所不同。实际股票市场上 每次股票买卖通常总有交易费,例如按交易额的1%收取交易费,这时你是否仍需要对所持 的股票进行买卖(换手),以便满足优解的要求?
: l" _: l0 r1 l& ] E+ q) p
_8 ~+ t* D' G. j
(1)建立模型
0 h) ]( c% W. }( ]+ a
; ~$ x0 {- ]4 G' H4 e+ A4 W( ^
仍用决策变量 分别表示投资人应当投资股票 A 、B 、C 的比例,进一步假设购买股票 A 、B 、C 的比例为 2
,卖出股票 A 、B 、C 的比例为
。其中,
和 ( i=1,2,3 )中显然多只能有一个严格取正数,且
$ p6 w& Q0 W; e6 x0 F) D
- j5 r8 I( k& P: x( M9 w& X
( 6 )
3 w- s1 m& A" `8 Z$ x
" _1 a% c1 Z+ s1 L; T {/ W
由于交易费用的存在,这时约束
不一定还成立(只有不进行股票买卖,即
时,这个约束才成立)。其实,这个关系式的本质是:当前持有的总资金是守恒的,在有交易成本(1%)的情况下,应当表示成如下形式:
6 g2 _" N! G* _" g- r% K2 ]
# z8 B/ O& \" _
( 7 )
1 r$ p+ k# H6 ^ s
' x; [ f! A7 P/ x# A
另外,考虑到当前持有的各只股票的份额
之间也应该满足守恒关系式
: a; Y; S7 y% S7 O3 {& G
# |2 {9 A3 f# a5 q: ?, @& f
( 8 )
\9 m. r* _0 m% a1 r d- C
- _# H; T% Q2 ?
(2)模型求解
, W- Y5 U) Y, U
: t7 C, |; Y6 E5 I4 p3 Z1 C; q
问题对应的LINGO程序如下:
_; [. X& f0 `' ?3 j, N6 }: f
: ]5 h" y9 n$ m: [$ P
MODEL:
" K/ _* b0 W% e/ t8 t) F( L) G- Q: _: l
Title 考虑交易费的投资组合模型;
7 \0 y' ?( k' |4 q
SETS:
- f6 V, A! Y, o
STOCKS/ A, B, C/: C,Mean,X,Y,Z;
2 R' ], m/ Z9 m# o* g. y
STST(Stocks,stocks): COV;
7 \6 g: h- K* Z. @3 R# d$ ^
ENDSETS
4 ?& e0 |6 G0 Q5 ^
DATA:
5 W( r( F8 i7 s: i0 c8 [
! 股票的初始份额;
6 F- N5 }/ Z( Z& N3 h+ Q
c=0.5 0.35 0.15;
. H, Q {& k8 @7 C
TARGET=0.15;
2 Z1 H [2 Q( V' }& A: Z
Mean=@file(data2.txt);
2 b' v6 J w2 B
COV=@file(data3.txt);
1 L5 ]3 `# }. |0 h6 F4 m( [% m
ENDDATA
$ x6 }+ Z7 [+ U# q+ w2 X1 q
[OBJ] MIN = @sum(STST(i,j): COV(i,j)*x(i)*x(j));
' t4 i' Q E. |8 {
[ONE] @SUM(STOCKS: X+0.01*Y+0.01*Z) = 1;
1 I% o; P7 s0 s: h" m- I! Q
[TWO] @SUM(stocks: mean*x) >= TARGET;
7 ^3 y& G; o% N! `$ t+ x
@FOR(stocks: [ADD] x = c + y - z);
" }! \7 z/ D9 h1 q
END
9 \, v' G! [2 [# B
在这个LINGO模型中,股票C是原始集合“STOCKS”的一个元素,不会因为与集 合的属性C同名而混淆。这是LINGO新版本比LINGO旧版本的一个改进之处。
: t8 t9 A" R: ?) S p
$ b/ ?0 P( }( {7 u7 M
& o$ ^+ C7 W- W5 x
+ G& G0 q+ e$ {! [! E# j6 W4 r/ b+ v5 h
利用股票指数简化投资组合模型
7 E, s. T, z3 ~
例8 继续考虑例5(期望收益率仍定为15%)。在实际的股票市场上,一般存在 成千上万的股票,这时计算两两之间的相关性(协方差矩阵)将是一件非常费事甚至不可能的事情。例如,1000只股票就需要计算
=499500 个协方差。能否通过一定方式避免协方差的计算,对模型进行简化呢?例如,例5中还给出了当时股票指数的信 息,但我们到此为止一直没有利用。我们这一节就考虑利用股票指数对前面的模型进行 修改和简化。
$ \; D! e: Y: q. L" `
- y3 B+ K# V1 m; d# {
(1)问题分析
, ^4 j4 H$ r* u) f V8 M- q
" x7 L$ @: q2 g
可以认为股票指数反映的是股票市场的大势信息,对具体每只股票的涨跌通常是有 显著影响的。我们这里简单地假设每只股票的收益与股票指数成线性关系,从而可以 通过线性回归方法找出这个线性关系。
: b {) m- R. a! E4 S/ Z
3 U2 j& L; N( Y0 F0 x# _4 [9 V
(2)线性回归
5 P) ?$ x. R; ]% r* E. f
: G0 j6 x' ^! h/ X# _, V# y
具体地说,用M 表示股票指数(也是一个随机变量),其均值为
,方差为
。根据上面的线性关系的假定,对某只具体的股票i,其价值
(随机变量)可以表示成
% R9 K! g& @: v9 m, `" G r
(9)
1 v3 i6 F, V0 }
4 Y7 N* k, J" {# d, M
其中 和 需要根据所给数据经过回归计算得到, 是一个随机误差项,其均值为
,方差为
。此外,假设随机误差项
与其它股票 j( j ≠ i )和股票指数M 都是独立的,所以
。
9 [( z {- x: a: w. m
( b# x! d, M, f
先看看如何根据所给数据经过回归计算得到
和
。记所给的12年的数据为
,( k =1,2,..,12),线性回归实际上是要使误差的平方和小,即要解如下优化问题:
0 H' R2 G c) Y
: L6 z s9 M5 V% v
(10)
4 W' D% q% Q, ]# E
% Y% `1 W* K0 f" v
对这里给出的三种股票,可以编写如下LINGO程序求出线性回归的系数
和
(同时也在计算(CALC)段计算M 的均值
和方差
,标准差
的值):
3 X" J! g: e/ I! W# v/ i& {+ w) V
! j% V8 L" `3 j& z) A+ p1 p% q
MODEL:
7 {5 e @; Q+ y; o
Title 线性回归模型;
) W* ~! W( _' M& m
SETS: YEAR/1..12/:M;
% K5 R0 X! @/ L9 `
STOCKS/A, B, C/: u, b, s2, s;
& Q* b9 `6 b2 U- s! b6 N( F* a
temp/1..5/;
& I& V$ }1 b6 b/ @3 [
tmatrix(YEAR,temp):tm;
+ t3 D/ H& i. I- E
link(YEAR, STOCKS): R, e;
/ G! z3 i) _. ]. G0 k2 X6 g
ENDSETS
4 e* u, K5 t' H/ t- i
DATA:
) Q. M) X% f4 y: \2 y8 f s" j
num=?;
* [% U$ B' ~7 U$ F$ y
tm =
$ b. w6 b: G( O8 W: A0 }. R7 f. s) V
1943 1.300 1.225 1.149 1.258997
7 w) Y- l8 i* D" \/ O' L
1944 1.103 1.290 1.260 1.197526
9 ^2 ?8 `$ l0 p1 C. _
1945 1.216 1.216 1.419 1.364361
( K. g1 m. N$ B( D2 a0 l
1946 0.954 0.728 0.922 0.919287
x) l" }* J3 h o. v3 j& c
1947 0.929 1.144 1.169 1.057080
2 y! U( d8 a o* ~0 _
1948 1.056 1.107 0.965 1.055012
' Y+ }3 \% w N, m" A+ {8 z( h
1949 1.038 1.321 1.133 1.187925
2 K8 w6 W% r; W' X: u8 @
1950 1.089 1.305 1.732 1.317130
1 i$ b% P9 R& I+ X+ |: T" O* j
1951 1.090 1.195 1.021 1.240164
1 A+ F; `4 i! D) _
1952 1.083 1.390 1.131 1.183675
6 h3 u6 n7 V, b& B3 W
1953 1.035 0.928 1.006 0.990108
3 b- `" ?* @6 o( X. [2 M
1954 1.176 1.715 1.908 1.526236;
2 y; t0 f/ ?& w# q
ENDDATA
: h1 d( k5 C3 J' j' @! v/ P
CALC:
+ V' U8 y; @3 q. q( M
@for(tmatrix(i,j)|j #ge#2 #and# j #le# 4:R(i,j-1)=tm(i,j));
1 x6 |( J$ y& Y" w' |/ y
@for(tmatrix(i,j)| j #eq# 5:M(i)=tm(i,j));
* |5 c& U8 f. f+ @; P1 i( m
mean0=@sum(year: M)/@size(year);
' J7 c- g! D" V6 x4 J
s20=@sum(year: @sqr(M-mean0)) / (@size(year)-1);
- x" }/ T- O* v1 c( m" Y! n3 a, C' V
s0=@sqrt(s20);
# z& L+ g. \) V4 x6 `6 Z
ENDCALC
9 ]. f P3 x, @2 L4 `* X0 e# X/ V
[OBJ] MIN = @sum(stocks(i)|i#eq#num: s2(i));
0 V0 @. H- z$ @8 G/ ]
@for(link(k,i)|i#eq#num: [ERROR] e(k,i) = R(k,i)-u(i)-b(i)*M(k)); @for(stocks(i)|i#eq#num:[VAR] s2(i)=(@sum(year(k): @sqr(e(k,i))) / (@size(year)-2)); [STD] s(i)=@sqrt(s2(i)) );
* R1 g1 x1 J1 ]
@for(stocks: @free(u);@free(b) );
1 t5 z. J% [0 @8 X
@for(link: @free(e) );
4 `* r+ E( A& p5 |6 \9 I$ s, W
END
% c& _+ s( g( n* T2 X* a
对上面的这个程序,请注意以下几点:
@+ S- d- M; i- T9 q
! S s3 d2 K( `
i)在CALC段直接计算了M 的均值
和方差
(为了使这个估计是无偏估计,分母是11而不是12)以及标准差
。
+ U/ F) X; |0 S2 V6 F. G; Z
& W, U: O( G1 w2 c8 Y
ii)程序中使用了两个常用的数学函数:平方函数@sqr和平方根函数@sqrt。
+ l( v. h, o, ^
' O! M! B, B' ?3 }) @$ b! F
iii)除了计算回归系数外,我们同时估计了回归误差的方差
和标准差
。为了使这个估计是无偏估计,计算
时分母是10而不是11或12,这时因为此时估计了两个参数,自由度少了两个。
, P0 Q( ?: E$ p& {: v8 p; z2 G
* K# B1 H5 H9 q, A3 R+ K5 ?" s
iv)@free(u),@free(b),@free(e)三个语句一定不能少,因为这几个变量不一定是非负的。
8 g+ Z& }0 J; @
2 H a. w6 z3 P
v)DATA段定义了一个变量num,并用“num=?”语句表示其具体值需要由使用者在程序 运行时输入。变量num的作用是控制当前对哪只股票进行线性回归(num=1,2,3分别对应于股票 A , B, C)。
3 }" G0 ]) o6 T+ t/ c
$ n( l/ Z' g1 H
vi)其实,这个问题也可以对三只股票的回归不加区分,即放在同一个模型中同时优化(相应地,只需要去掉上面程序中的控制变量num和所有的过滤条件“i#eq#num”),不 过这样就会增加变量的个数,我们不建议大家那样做。也就是说,对于能够分解成小规模 问题的优化问题,好一个一个分开做,这样可以减少问题规模,有助于求到比较好的解。
- W2 p* F3 p* U) o# H' X
' U" P6 x. n4 u
运行上述LINGO程序,得到的计算结果为:股票指数M 的均值 = 1.191458 ,方差为
=0.02873661 ,标准差为
= 0.1695188 ;对股票 A,回归系数
= 0.5639761,
= 0.4407264 ,误差的方差
= 0.00574832 ,误差的标准差
= 0.07581767 。
' z* ~ v$ `* }! t+ N
& M+ Y1 {/ A- E( a @
同理(运行时输入num=2或3),可以得到:对股票B ,回归系数
= - 0.2635028 ,
= 1.239799 ,误差的方差
= 0.01564263 ,误差的标准差
= 0.1250705 。对股票C ,回归系数
= - 0.5809592 3 ,
= 1.523798 ,误差的方差
= 0.03025165 ,误差的标准差
=0.17393 。
7 j: k# f1 `( s' ~$ D
- e* D6 [* p' _0 H
(3)优化模型
& l. t8 A S- q# X' p+ X: C
: o/ [0 K6 v& k( q9 U
现在,仍用决策变量
分别表示投资人应当投资股票 A ,B ,C 的比例,其中
( e) |" C2 x1 D% _0 g
: {% f3 M+ \, m9 \1 t
(11)
3 t0 i0 H1 ? }( W
8 ~* j' Y6 }- ]& u
此时,与第1节的讨论类似,对应的收益应该表示为
% _3 S, s, _! r v3 e) I( l
, d1 C" k& F n: g/ K6 K; r( S# ~
; M" g+ g/ d) t
/ O0 u) h# S' W/ [
(4)模型求解
+ i: Z8 u l1 W3 m y" Q5 \& Q
+ N: \& n. V+ D& b, I8 o
为了数据传递方便,我们把三个回归模型同时计算。LINGO程序如下
0 j% I+ I1 [( x4 r
! Y8 I) m' p1 `3 I+ q' Q
MODEL:
, M7 T. K% {9 H3 y4 a
Title 线性回归模型;
( q4 s! e& ?2 t0 g) l; }
SETS:
5 Q' a1 c( Q) J p; r5 t
YEAR/1..12/:M;
8 e4 k. Q( W# l8 k! [% X
STOCKS/A, B, C/: u, b, s2, s;
& b8 f+ w; k/ o. J
temp/1..5/;
: {8 N1 r. q' g' H3 }
tmatrix(YEAR,temp):tm;
" q* \/ F& Y, ?5 X
link(YEAR, STOCKS): R, e;
5 z6 W0 |6 O! M
ENDSETS
: \: s* V# D; S3 m G4 Q/ M, |* I6 U
DATA:
$ \2 ?: k& A3 Z6 }
tm =
1 v5 `7 i9 D$ x# D
1943 1.300 1.225 1.149 1.258997
6 [. x6 |0 F0 ^! `, N; r
1944 1.103 1.290 1.260 1.197526
+ \" w2 z5 ]; v0 l# D
1945 1.216 1.216 1.419 1.364361
7 j' R; L# X! X! u
1946 0.954 0.728 0.922 0.919287
; P" Z1 v8 ]$ a6 ^% {/ j
1947 0.929 1.144 1.169 1.057080
, r9 n/ n( c+ D
1948 1.056 1.107 0.965 1.055012
5 c ?3 e* t5 c7 w/ _; ?
1949 1.038 1.321 1.133 1.187925
8 v7 d! p) P% i& `) L* x& _) z
1950 1.089 1.305 1.732 1.317130
9 Y4 C) l1 m. f8 ?
1951 1.090 1.195 1.021 1.240164
+ A }9 u3 }, N7 c
1952 1.083 1.390 1.131 1.183675
1 ~$ c) i: n) H+ C4 [
1953 1.035 0.928 1.006 0.990108
1 J! ]6 Q7 [4 C% t. P
1954 1.176 1.715 1.908 1.526236; @text('data4.txt')=s2;
- M/ B# D/ v. R4 R, d' W
@text('data5.txt')=u;
$ J/ p0 b" q9 t: \/ }$ p$ R
@text('data6.txt')=b;
% Z5 T' c1 G2 Z# |# v+ @
ENDDATA
! ?' ]: Q% }7 f1 f
CALC:
# t- Z* ?4 m1 R* Y# x# \& r
@for(tmatrix(i,j)|j #ge#2 #and# j #le# 4:R(i,j-1)=tm(i,j));
) ?; S3 n) R [9 U# U3 L h
@for(tmatrix(i,j)| j #eq# 5:M(i)=tm(i,j));
7 F/ c/ G; Y# N" B; q, P0 M7 F0 U( I
mean0=@sum(year: M)/@size(year);
" P) f1 }# D7 E0 p( l9 B
s20=@sum(year: @sqr(M-mean0)) / (@size(year)-1);
) M. K( W2 m# J/ m1 \. j/ S
s0=@sqrt(s20);
3 G" P! T) \) J: H
ENDCALC
' e( r* e5 F; }9 Z, I
[OBJ] MIN = @sum(stocks(i): s2(i));
G6 P7 d1 O* \
@for(link(k,i): [ERROR] e(k,i) = R(k,i)-u(i)-b(i)*M(k));
4 ? [, _: c0 A9 _! j7 K( C1 c
@for(stocks(i):[VAR] s2(i)=(@sum(year(k): @sqr(e(k,i))) / (@size(year)-2));
% _- R" k$ A! z4 f
[STD] s(i)=@sqrt(s2(i)) );
, N( ]! L; {/ q [' c
@for(stocks: @free(u);@free(b) );
4 S+ F- b" U3 n9 K+ i
@for(link: @free(e) );
7 s3 ]7 A- A: ^& D" t" x
END
7 r* M4 T% H1 `1 H4 Y' G2 u3 }
上述二次规划的LINGO程序如下:
0 c# f6 I4 z" |6 f
2 Q1 {1 A9 f( F3 B6 D1 J
MODEL:
3 X0 q' W! W _" n, \
Title 利用股票指数简化投资组合模型;
; t) F7 b, D% H& o0 G5 `- |+ b/ C
SETS:
1 w6 g- G5 |9 Z9 R2 Q. z# X
STOCKS/A, B, C/: u, b, s2, x;
3 @. q$ o& Z5 F/ {
ENDSETS
0 I# t+ v2 v" `- H& w
DATA:
4 E2 [1 i% H9 t- J |3 j0 J
mean0=1.191458;
& i0 `, R9 f' r) n; b. I% I, p& {
s20 = 0.02873661;
5 o5 f* F* S: A' D
s2 = @file(data4.txt);
: H! ~+ Z8 G' N9 q
u = @file(data5.txt);
' M i* G% ~' T. D* j, V
b = @file(data6.txt);
) X. E; H& z# ^+ Z
ENDDATA
9 K4 `8 ~/ p7 f# v6 l& |2 |' e
[OBJ] MIN = @sum(stocks: (@sqr(b)*s20+s2)*@sqr(x));
( l* O4 O" w- p
@sum(stocks: x)=1;
1 ^5 M; ?# e+ g5 u5 Z4 ?, Y& g( w
@sum(stocks: (u+b*mean0)*x)>1.15;
: |$ u$ l1 X8 k Q+ A
END
6 w( `" \. U1 n2 m( l/ H
计算结果为,最后的持股情况是:A大约占初始时刻总资产的54%,B 占27%,C 占19%。这个结果与例5的结果是不同的。
) h* ^3 D# E/ F; H# g2 M6 t5 G
2 @9 a2 O, P& T; _7 q8 M: d
其它目标下的投资组合模型
8 X4 r( ?8 k6 A7 O2 e, x
前面介绍的模型中都是在可能获得的收益的数学期望满足一定低要求的前提下, 用可能获得的收益的方差来衡量投资风险,将其作为小化的目标。这种做法的合理性 通常至少需要有两个基本假设:
$ ~5 Z( e2 L4 y1 g& L' F
3 S. X1 ] l6 @$ N
(1)可能获得的收益的分布是对称的(如正态分布)。因为这时未来收益高于设 定的低要求和低于设定的低要求的数量和概率是一样的。可惜的是,实际中这个假设往往难以验证。
1 P: }. U; c4 g& z5 Y
) |) ^: r! M% R( c8 i7 ?7 @
(2)投资者对风险(或偏好)的效用函数是二次的,否则为什么值选择效益(随 机变量)的二阶矩(方差)来衡量风险使之小化,而不采用其它阶数的矩? 一般来说,投资者实际关心的通常是未来收益低于设定的低要求的数量(即低多 少)和概率,也就是说更关心的是下侧风险(downside risk)。所以,如果分布不 是对称的,则采用收益的方差来衡量投资风险就不一定合适。为了克服这个缺陷,可以 用收益低于低要求的数量的均值(一阶矩)作为下侧风险的衡量依据,即作为最小化 的目标。此外,也可以采用收益低于低要求的数量的二阶矩(即收益的半方差, semivariance)作为衡量投资风险的依据。其实,半方差计算与方差计算类似,只是只有当收益低于低要求的收益率时,才把两者之差的平方记入总风险,而对收益高于低要求的收益率时的数据忽略不计。这方面的具体模型这里就不再详细介绍了。 下面介绍一个与上面这些优化目标完全不同的投资组合模型,这个模型虽然很简单,但却会产生一些非常有趣的现象。
# _- H( p6 X5 b4 s. t6 L
0 q& D- _0 I7 ~6 c9 O' I
例9 假设市场上只有两只股票 A, B可供某个投资者购买,且该投资者对未来一年的股票市场进行了仔细分析,认为市场只能出现两种可能的情况(1和2)。此外, 该投资者对每种情况出现的概率、每种情况出现时两只股票的增值情况都进行了预测和 分析(见表7,可以看出股票 B A、 的均值和方差都是一样的)。该投资者是一位非常 保守的投资人,其投资目标是使两种情况下小的收益最大化(也就是说,不管未来发生哪种情况,他都能至少获得这个收益)。如何建立模型和求解?
8 @2 S' u+ u( I- }* E
7 b3 L7 {0 g+ O* C" M1 o
( v7 W5 z" ~2 {8 @1 M) a1 ^) J% g
3 G& h( V% x+ g4 w: k
(1)优化模型与求解
0 }) }- T+ u, A2 K8 |% A
, l e0 _1 p. u, J6 w$ Z- z% c" ~
设年初投资股票A、 B 的比例分别为
,决策变量
显然应该满足
# n8 i0 J! C- r4 K) a/ ` ?# z4 Q
(12)
# n7 u) J# z; ?
此外,使最小收益最大的“保守”目标实际上就是希望:
6 Y0 Q3 C& `3 n/ N' c: l/ P
1 s+ r7 p1 ]% L5 b
% K. W: l9 {8 ~! B0 K" r4 N
引入一个辅助变量
! C& D; V: B" M: Q
; `1 l. m6 I8 t- \' [. k
$ c% g- L, ?' _+ g
# b& S8 O/ M6 p4 p6 p
这个模型就可以线性化为
% z+ P) t; B' o$ Z
$ o" w8 H5 _/ `$ ~" V/ u( o
5 ]3 X T. W, c/ B0 S
: ^5 A6 Y0 l. s% A0 K
编写LINGO程序如下:
9 _ g4 C& S1 d/ }7 n
( g* p6 m7 m# n: Z4 M* X9 `
model:
: [! ]- i8 A+ m) T3 t
sets:
! g) `: e: N7 j+ N# E: z
COL/1..2/:x;
2 h- |9 _9 {& O3 `* G! O( [% Q5 {
ROW/1..2/;
$ M. U M/ ~$ f! K
link(ROW,COL):a;
+ o. o3 @2 h6 w& w( p( v; L
endsets
& O/ R+ v# Q% x( }' l6 ?% h( T# \
data:
8 K2 b3 J# L2 ]" K
a=1 1.2 1.5 0.7;
6 U/ |* n0 u& \( N$ h
enddata
* M* E5 |, x0 b; p1 R! q
max=y;
3 f' M( V$ H3 M2 a4 k
@sum(COL:x)=1;
! N% u# P" k2 x; M' ^
@for(ROW(i)
sum(COL(j):a(i,j)*x(j))>y);
, {! { o5 d c' j# ~5 D" ~" @
End
7 w1 q' T8 ~3 Q5 |
可见,此时应该投资 A、B 股票各50%,至少可以增值10%。
0 K: k, v1 L( B/ f1 L# q4 I/ L n
" o( d& s" I% T8 G2 }- ]) |
(2)讨论
0 _" W& g3 M1 E+ F+ r: l* D7 J
" G* j, S" @: g; h2 F, J
现在,假设有一位绝对可靠的朋友告诉该投资者一条重要信息:如果情形1发生, 股票B 的增值将达到30%而不是表7中给出的20%。那么,一般人的想法应该是增加 对股票B 的持有份额。果真如此吗?这个投资人如果将上面模型中的1.2改为1.3计 算,将得到如下结果: =0.5454545 , = 0.4545455 , y=1.136364 。
* ?1 I4 k4 x! v$ \ G
0 W. t) Z9 r2 J/ l# L: a
也就是说,应该减少对股票B 的持有份额,增加对股票 A的持有份额。这真是叫 人大吃一惊!这相当于说:有人告诉你有某只股票涨幅要增加了,你赶紧说:那我马上 把这只股票再卖点吧。之所以出现如此奇怪的现象,就是由于这个例子中的目标的特殊 性引起的:我们可以看到新的解可以保证增值达到13.6364%,确实比原来的10%增 加了。
' f! T" ?, W1 h% K! Z4 D
2 E/ n* l2 p3 j) X+ D5 ]7 s
最后需要指出:我们上面所有关于投资组合的这些讨论基本上只是纯技术面的讨 论,只利用历史数据来说话,认为历史数据中包含了引起股票涨跌的所有因素。在实际 股票市场上,影响股票涨跌的因素可能有很多(如政策变化、银行加息、能源短缺、技 术进步等),未来不长时间内可能发生的一些重大事件很可能以前没有发生过,因此也 不可能体现在历史数据中。所以,进行投资选择前,还应该进行基本面分析,需要对未 来的一些重要影响因素、重大事件发生的可能性及其对每种股票涨跌的影响进行预测和分析,最后综合利用历史数据和这些预测数据,决定投资组合。如何将这些预测数据与 历史数据一起使用,建立相应的投资组合模型,这里就不再更多地介绍了。这方面的模 型有很多,有兴趣的可以继续查阅相关的专业书籍和研究文献。
$ g. B# T: e7 N2 @, Y: j9 T6 O; N
4 X, J3 U+ e _( U. X
习题:
c4 O' p# m) F4 k& `; p9 s! B5 h
/ ^: \6 O, i% F# q r0 j/ ?
某银行经理计划用一笔资金进行有价证券的投资,可供购进的证券及其信用等 级、到期年限、收益如表11所示。按照规定,市政证券的收益可以免税,其它证券的 收益需按50%的税率纳税。此外还有以下限制:
3 H" M2 z. q4 H( j3 T, @
2 Q, D5 y. ~ J7 V
i)政府及代办机构的证券总共至少要购进400万元;
X! x @+ t+ _- h& A
; v* Q8 _/ ]$ W# i- B# b
ii)所购证券的平均信用等级不超过1.4(信用等级数字越小,信用程度越高);
8 }2 \. \' n$ b0 E5 A
7 S& O' M1 H& }) N3 H6 K8 C7 L) _) r
iii)所购证券的平均到期年限不超过5年。
1 h$ M; X/ ?6 B4 p# c5 g
% O6 g) w% H$ a
F. o" H9 P% N) Y2 P& |
4 Z; p& J% Q d% F7 J& X# D
(1)若该经理有1000万元资金,应如何投资?
5 U- Y3 C2 x: {# }8 G- \! i: p- N
D. U7 ~* k, a" @4 a
(2)如果能够以2.75%的利率借到不超过100万元资金,该经理应如何操作?
/ l# [$ `( Y, _8 K# y
9 {; i2 L, _( n2 V2 \& i% f
(3)在1000万元资金情况下,若证券 A的税前收益增加为4.5%,投资应否改变? 若证券C 的税前收益减少为4.8%,投资应否改变?
' n! J! s' G- \8 o
————————————————
: ~4 G" K, o: j
版权声明:本文为CSDN博主「wamg潇潇」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
/ h8 L8 k4 p- p& i2 T6 s
原文链接:https://blog.csdn.net/qq_29831163/java/article/details/89406997
) J, B: `/ g* ]" r6 n+ j! ]
- ]% c. m8 c! q
" S+ l3 v f" a% C/ w% Z8 ]( M
欢迎光临 数学建模社区-数学中国 (http://www.madio.net/)
Powered by Discuz! X2.5
 6 ~4 C$ H- b6 B5 {4 n8 r- [' W7 x4 H
6 ~4 C$ H- b6 B5 {4 n8 r- [' W7 x4 H
 ( 4 )
( 4 )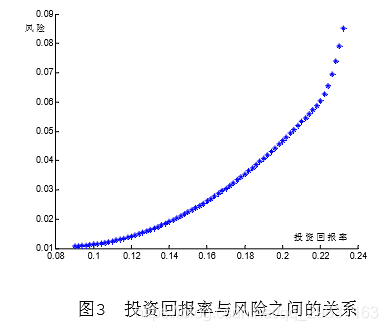 & i, H8 L) P" L* l7 u2 I9 s" X
& i, H8 L) P" L* l7 u2 I9 s" X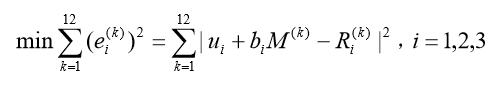 (10)
(10) ; M" g+ g/ d) t
; M" g+ g/ d) t
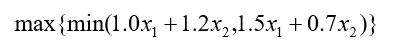 % K. W: l9 {8 ~! B0 K" r4 N
% K. W: l9 {8 ~! B0 K" r4 N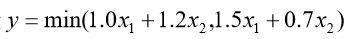
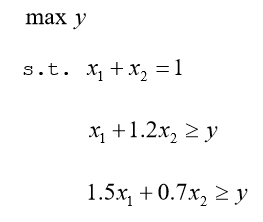
 sum(COL(j):a(i,j)*x(j))>y);
sum(COL(j):a(i,j)*x(j))>y);