数学建模社区-数学中国
标题: 真题解析论文版:2020国赛C题:中小微企业的信贷决策 [打印本页]
作者: 普大帝 时间: 2022-5-18 10:24
标题: 真题解析论文版:2020国赛C题:中小微企业的信贷决策
本题基于国产SPSS软件SPSSPRO操作,相较于SPSS软件,操作便捷无需编程也能轻易上手,但算法还是必须要懂的,不然算法模板再多你也无从下手啊!想要学习SPSSPRO操作,数学中国网站搜索即有大量教程等你来拿! V# f1 |4 E+ W2 c# `/ Q$ g
1、题目背景在实际中,由于中小微企业规模相对较小,也缺少抵押资产,因此银行通常是依据信贷政策、企业的交易票据信息和上下游企业的影响力,向实力强、供求关系稳定的企业提供贷款,并可以对信誉高、信贷风险小的企业给予利率优惠。银行首先根据中小微企业的实力、信誉对其信贷风险做出评估,然后依据信贷风险等因素来确定是否放贷及贷款额度、利率和期限等信贷策略。
6 X2 {' s2 {, g' l8 U X某银行对确定要放贷企业的贷款额度为10~100万元;年利率为4%~15%;贷款期限为1年。附件1~3分别给出了123家有信贷记录企业的相关数据、302家无信贷记录企业的相关数据和贷款利率与客户流失率关系的2019年统计数据。该银行请你们团队根据实际和附件中的数据信息,通过建立数学模型研究对中小微企业的信贷策略,主要解决下列问题:/ d' P+ U( E& g) d1 b; B
(1) 对附件1中123家企业的信贷风险进行量化分析,给出该银行在年度信贷总额固定时对这些企业的信贷策略。
$ x( g' t# W6 E( n9 _! k(2) 在问题1的基础上,对附件2中302家企业的信贷风险进行量化分析,并给出该银行在年度信贷总额为1亿元时对这些企业的信贷策略。
; m; B* z/ [9 a(3) 企业的生产经营和经济效益可能会受到一些突发因素影响,而且突发因素往往对不同行业、不同类别的企业会有不同的影响。综合考虑附件2中各企业的信贷风险和可能的突发因素(例如:新冠病毒疫情)对各企业的影响,给出该银行在年度信贷总额为1亿元时的信贷调整策略。1 r$ R4 w$ N% u$ ~* N
* x- l. y5 Y/ z- b1 a, J) k附件1 123家有信贷记录企业的相关数据0 W+ E: b% L4 l% E0 b
附件2 302家无信贷记录企业的相关数据" j+ b( Q1 z' @
附件3 银行贷款年利率与客户流失率关系的2019年统计数据" i! e$ [/ G% a
# ]5 h3 Q2 h. @附件中数据说明:0 {) v* x6 W; r1 c2 k, n8 j6 B/ U
(1) 进项发票:企业进货(购买产品)时销售方为其开具的发票。, T8 c. `% ]7 K! N; k% {
(2) 销项发票:企业销售产品时为购货方开具的发票。' Z8 \$ k" m% ]% R
(3) 有效发票:为正常的交易活动开具的发票。
. X" t) G, ~6 _(4) 作废发票:在为交易活动开具发票后,因故取消了该项交易,使发票作废。
4 ]( H! F7 R+ O$ k/ W. Q4 I8 q(5) 负数发票:在为交易活动开具发票后,企业已入账记税,之后购方因故发生退货并退款,此时,需开具的负数发票。5 Q; H* F7 y( E( A
(6) 信誉评级:银行内部根据企业的实际情况人工评定的,银行对信誉评级为D的企业原则上不予放贷。- R$ \) d4 ~; _/ @$ P# E$ [1 `
(7) 客户流失率:因为贷款利率等因素银行失去潜在客户的比率。
2、总体解题思路2.1 第一问思路对附件1中123家企业的信贷风险进行量化分析,给出该银行在年度信贷总额固定时对这些企业的信贷策略。
这个问题问题可以理解为:对123家企业的信贷风险进行量化分析,然后给出对这些企业进行评级与分配信用贷款的方法。
; n8 t$ ?- g" A' J
& @- I4 d4 G7 |: H附件1:123家有信贷记录企业的相关数据(sheet1:企业信息)可以看到,这是银行已经对这些企业打的信用评级与确认出来的是否违约,我们需要做的就是:
把目前所能拿到的数据转化一列定量的数据用于评价信贷风险,然后根据这个比例来按进行分配贷款。
其大纲解题思路步骤如下:
尽可能地构造多的特征(X),以是否违约为Y,构造一个分类模型
只利用这个分类模型输出的预测概率,如【是否违约_否】的概率,也就把违规预测模型转为了信贷风险模型
将输出的概率进行归一化,如【是否违约_否】的概率进行归一化,然后按比例分配贷款
8 q5 v( G0 W0 a) A( P
关键点1:先对附件1的数据(其有是否违约这个变量)进行处理,附件2(其无是否违约这个变量)需要同步处理,保证构造的X一致;
- {. `. Z; {+ [8 a% ?关键点2:接着用验证且训练好的附件1数据的模型去预测附件2的是否违约(Y),产生概率用于分配贷款
这一题的改进策略有:
1,调整模型参数(效果微小),可以用启发式算法进行调优,如粒子群算法、遗传算法、模拟退火算法
2,扩充特征指标(效果中等),以便搜寻更多信息扩展更多指标特征
3,扩充样本数量(效果卓越),使用或者改进更优秀的采样算法,或者找到更多的训练样本数据
2.2 第二问思路在问题1的基础上,对附件2中302家企业的信贷风险进行量化分析,并给出该银行在年度信贷总额为1亿元时对这些企业的信贷策略。
这里可以直接给予问题2的模型,投入附件1的全部数据进行训练,训练后,预测附件2的是否违约(Y),产生概率用于分配贷款。
2.3 第三问思路这里要求给出信贷调整策略,原因是突发因素会对不同行业、不同类别的企业会有不同的影响,例如对互联网行业,新冠病毒疫情是促进的,但是对于旅游业,新冠病毒疫情则导致了其大萧条,可以做一个行业的分类,然后搜集数据进行赋权,有数据可以用熵权法,RSR等算法,而如果没有数据的情况下,可以采用层次分析法进行分析
3、具体解题步骤3.1 解题流程框图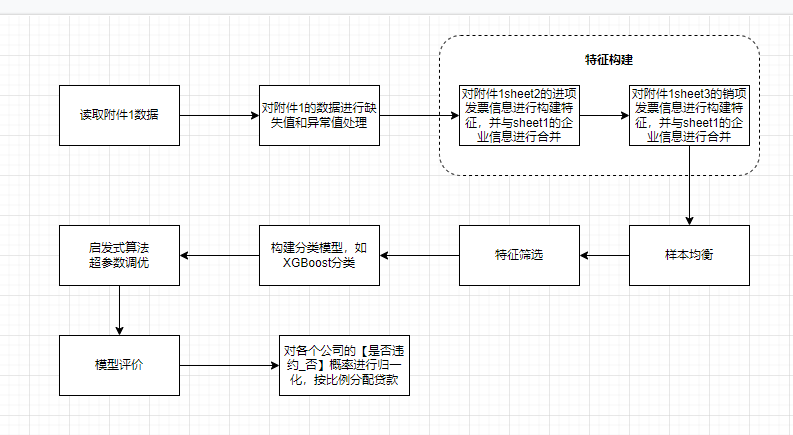 第一问解题流程
第一问解题流程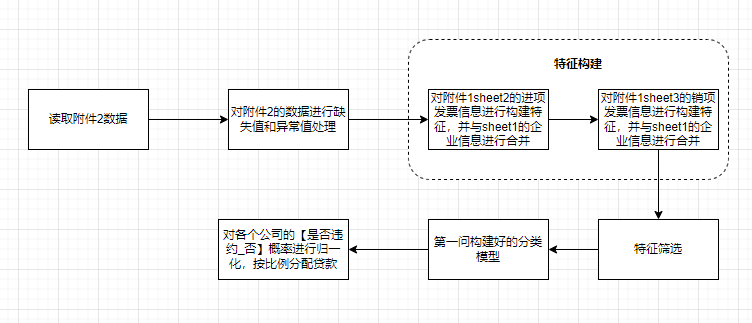 第二问解题流程
第二问解题流程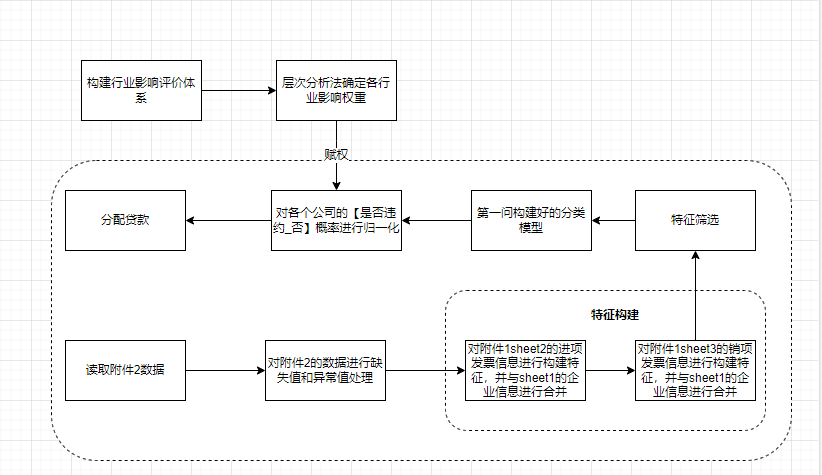 第三问解题流程
第三问解题流程
* B1 b4 b! ~6 r* S$ U# W3.2 详细解题步骤step1:读取附件1的三个合集数据
首先读取附件1的数据
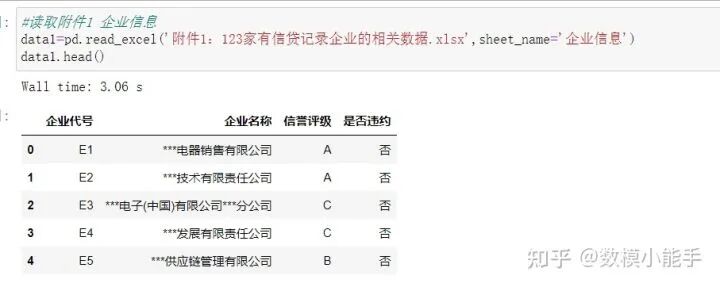 读取附件1 企业信息
读取附件1 企业信息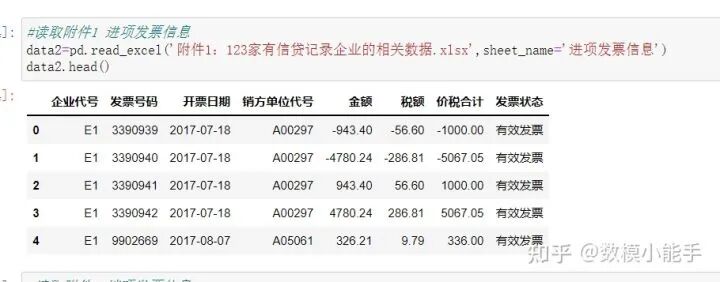 读取附件1 进项发票信息
读取附件1 进项发票信息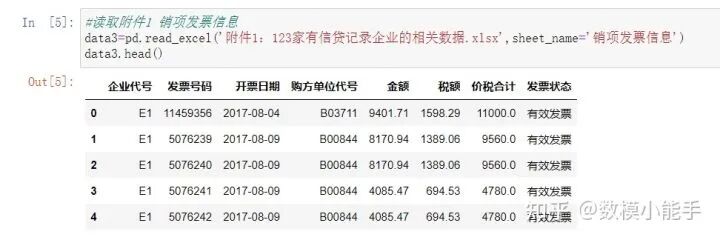 读取附件1 销项发票信息
读取附件1 销项发票信息- m1 ~' `1 F+ l3 ]. v
step2:对附件1的数据进行缺失值和异常值处理
先进行异常值处理,异常值处理需要先识别出来异常值,再进行替换填充,其识别方法有
 (1)MAD异常值处理
(1)MAD异常值处理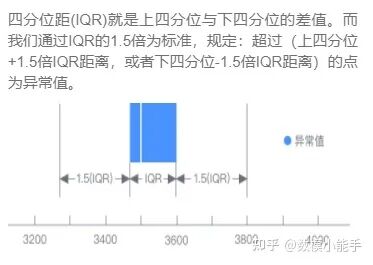 IQR识别
IQR识别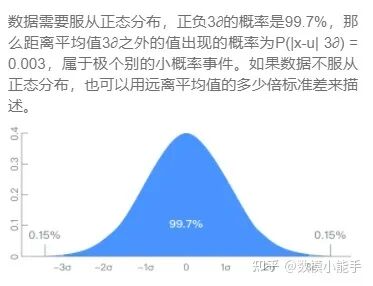 3sigema识别
3sigema识别将识别出来的缺失值标识为缺失值,进行填充,填充方法有普通的统计量填充,如均值、众数,正负三倍标准差等等;规则填充,如固定值填充、向上、向下填充等等;还有模型填充,如定量变量的缺失值可以用机器学习的回归算法进行填充、定类变量的缺失值可以用分类算法填充等等。
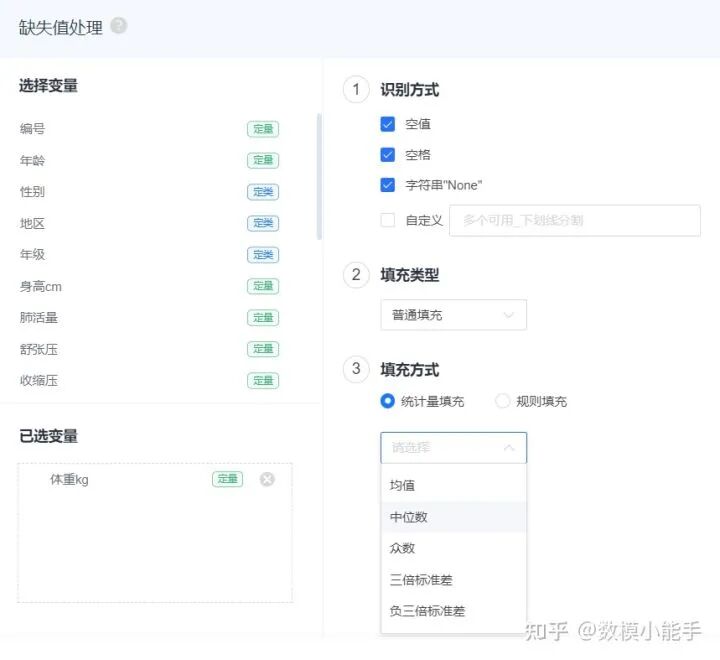 SPSSPRO中的缺失值处理 @# d2 n( s3 C+ _8 l4 a# y
SPSSPRO中的缺失值处理 @# d2 n( s3 C+ _8 l4 a# y
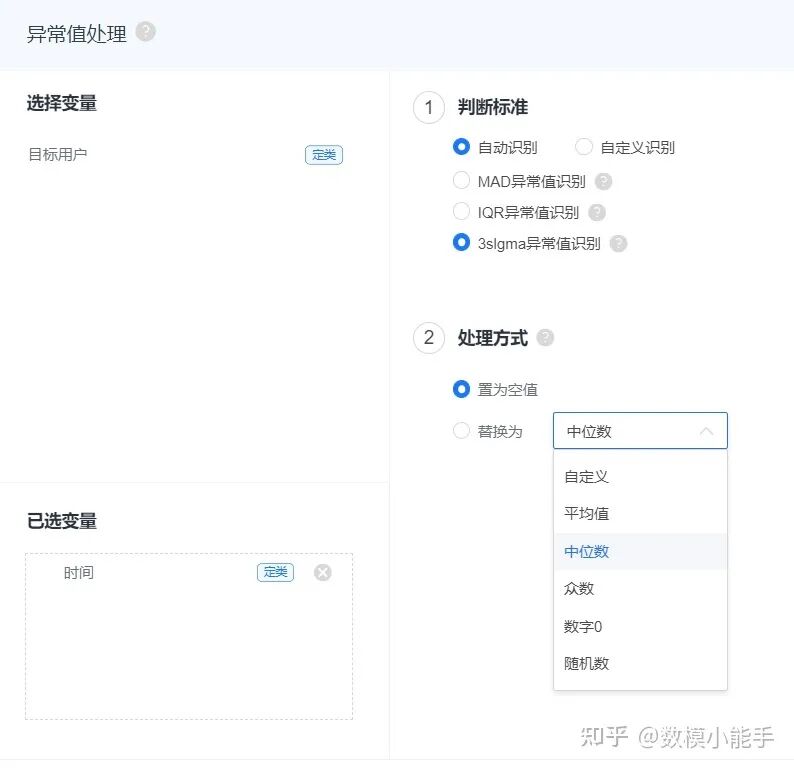 SPSSPRO中的异常值处理
SPSSPRO中的异常值处理step3:构建特征
对【是否违约】建立特征工程(尽可能构建多的特征),以特征工程为X,以【是否违约】为Y, 建立一个信誉评级分类模型。
特征工程也就是构建尽可能多的X:
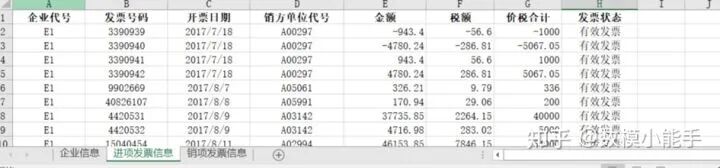 附件1:123家有信贷记录企业的相关数据(sheet2:进项发票信息)
附件1:123家有信贷记录企业的相关数据(sheet2:进项发票信息)例如进项发票信息页面,可以构造特征【金额】,【税额】,【价税合计】,【发票状态】这些明面上的指标,也可以是【对企业代号进行分组,拿到的总金额、平均金额、中位数金额】,【对企业代号进行分组,拿到的总税额、平均税额、中位数税额】,【对企业代号进行分组,拿到的总价税合计、平均价税合计、中位数价税合计】,同时还可以是【对开票日期(日周月年)进行分组,拿到开票的频数(日周月年)】,【累计开票数】,【累计有效发票个数】,【累计无效开票次数】。
 附件1:123家有信贷记录企业的相关数据(sheet3:销项发票信息)
附件1:123家有信贷记录企业的相关数据(sheet3:销项发票信息)对于【销项发票信息】,同理与上,可以构建。
构造特征工程可以采用Python进行编码
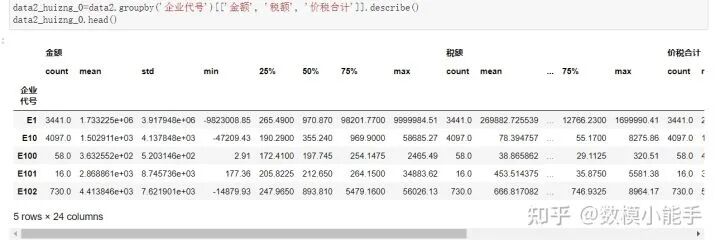 以企业代号为分组项,构造对金额、税额、价税合计这三个变量的特征
以企业代号为分组项,构造对金额、税额、价税合计这三个变量的特征以企业代号为分组项,对'金额', '税额', '价税合计'这三个变量提取计数、均值、标准差、最小值、1/4位数、1/2位数、3/4位数,最大值构造特征
可以看到,从3个变量衍生成了24个变量,当然了,这是属于比较粗糙的构造特征方法。
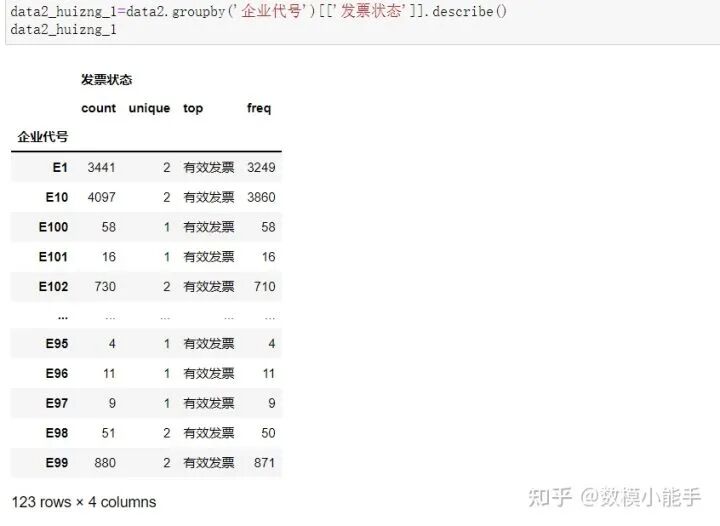 根据发票状态变量构造特征
根据发票状态变量构造特征根据发票状态变量,可以衍生出特征,发票状态个数,去重值,频数最高的发票状态类别,频数最高的发票状态类别对应频数
可以看到,又衍生成了4个变量
将构造好的两个特征列表合并,对附件1的
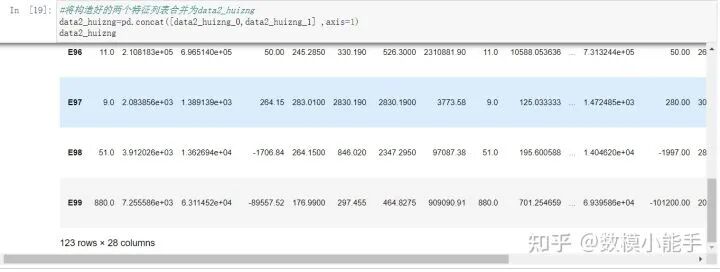 将构造好的两个特征列表合并
将构造好的两个特征列表合并将上面合并好的列表再跟data1进行合并,也就是企业信息的数据,合并得到数据union_data
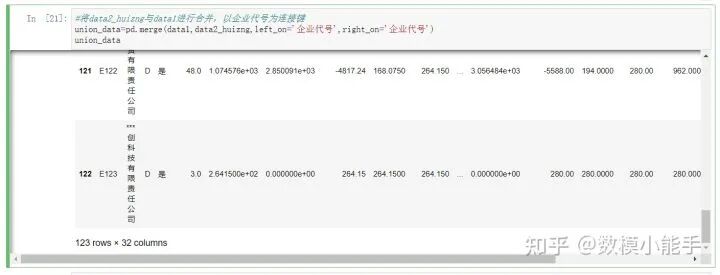 上面合并好的列表再跟data1进行合并
上面合并好的列表再跟data1进行合并重复以上步骤,同理处理data3,再与union_data进行合并
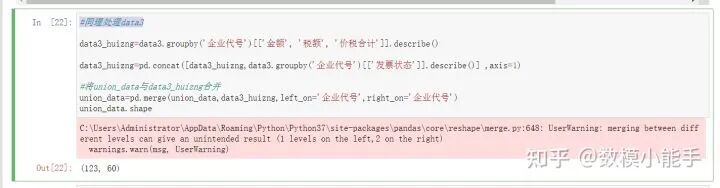 同理处理data3
同理处理data3 因为构造好的特征需要与附件2保持一致,因此剔除变量信誉评级
因为构造好的特征需要与附件2保持一致,因此剔除变量信誉评级可以看到,一共有123家企业数据,59-3=56项特征(X),Y是【是否违约】
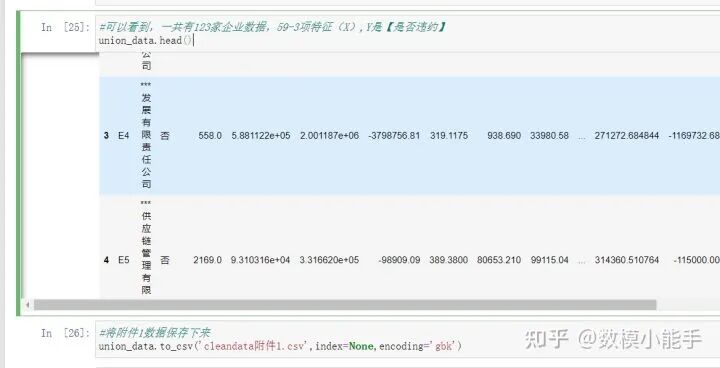 预览前5行数据并保存为cleandata附件1.csv
预览前5行数据并保存为cleandata附件1.csv' d* ]( k; g% a" A7 F
同时我们也可以根据企业名称来进行聚类,例如科技公司,地产公司,可以通用词向量聚类,也可以通过关键词进行聚类,这样又多了一个指标,【公司类别】
9 R; o8 {; N' ?8 I7 X& e6 C6 j还有【(日周月年)均净收入,净支出】(收入发票减支出发票)
总之,尽可能扩充特征工程,就我上面上代码展示的就有共计56个特征,当然,我们还是可以尽可能地多扩充,先不管这些特征是否存在共线性。
Step4:样本均衡
接着,我们需要对样本数据进行均衡处理,因为我们肉眼可以看到【是否违约】存在极大的样本不均衡,这些直接训练一个分类模型会导致模型过拟合,例如我有一百个样本,99个样本是1,那么即使我瞎分类,全部判为1,准确率也是99%,样本均衡可以通过过采样、下采样或者组合采样。
过采样:7 m2 i/ W/ ?0 ?& q
当数据不平衡的时,比如对于一个只用0和1的二分类问题,样本标签1有995个数据,样本标签0有5个数据时,为了保持样本数目的平衡,可以选择增加或通过算法生成标签0的数据量,这个过程就叫做上采样,也叫过采样。
3 Z) y8 b' }5 k) I下采样:
0 _' F; g6 V2 t8 t' b当数据不平衡的时,比如对于一个只用0和1的二分类问题,样本标签1有995个数据,样本标签0有5个数据时,为了保持样本数目的平衡,可以选择减少或通过算法减少标签1的数据量,这个过程就叫做下采样,也叫欠采样。
. A) N; n1 k) v2 r* D+ X' j组合采样:/ z* l# q% q1 U$ X) t5 }
结合上采样和下采样的方法,为了保持样本数目的平衡,可以选择通过算法减少或生成不均衡标签的数据量。
以smote过采样算法为例,其思想为:合成新的少数类样本,合成的策略是对每个少数类样本a,从它的最近邻中随机选一个样本b,然后在a、b之间的连线上随机选一点作为新合成的少数类样本。如图所示:
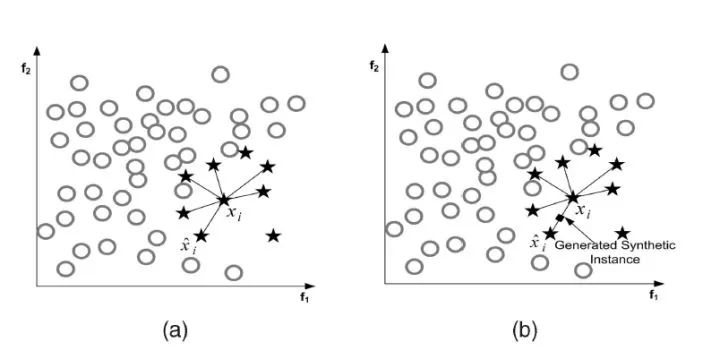
算法流程:
1、对少数类中每一个样本a,以欧氏距离为标准计算它到少数类样本集中所有样本的距离,得到其k近邻。
2、根据样本不平衡比例设置一个采样比例以确定采样倍率N,对于每一个少数类样本a,从其k近邻中随机选择若干个样本,假设选择的近邻为b。
3、对于每一个随机选出的近邻b,分别与原样本a按照如下的公式构建新的样本: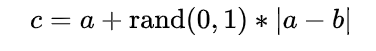
 SPSSPRO中的样本均衡算法
SPSSPRO中的样本均衡算法Step5:特征筛选
& R8 J/ k. q2 G8 ^: t" Q
由于构造的特征太多了,我们需要对特征进行筛选,这里我们需要减少特征,可以选择诸如主成分分析等降维技术进行数据降维,也可以使用随机森林特征重要度、递归消除特征法等筛选方法来进行特征筛选。
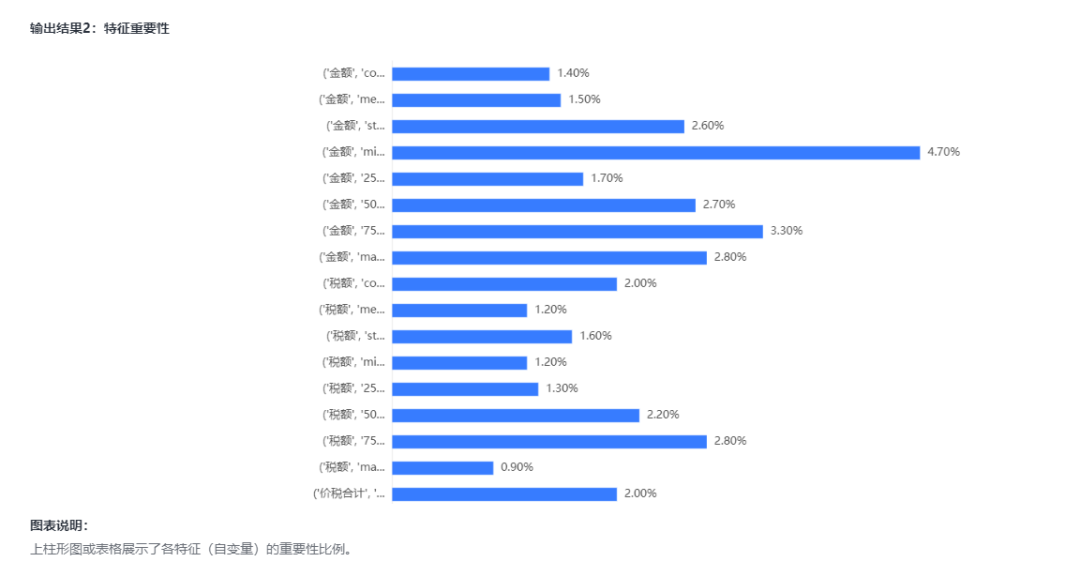 SPSSPRO随机森林特征重要性
SPSSPRO随机森林特征重要性Step6:模型分类
Q( o5 y ~, {: o7 p+ \
准备工作就绪,我们可以把他丢进一个分类模型进行序列,推荐逻辑回归或者XGBOOST与随机森林,需要对数据进行切分训练,评价指标可以选择F1,可以进行各种自由调参,例如启发式算法(PSO粒子群、遗传算法等等)保证模型的最优。
 SPSSPRO中的XGBoost分类
SPSSPRO中的XGBoost分类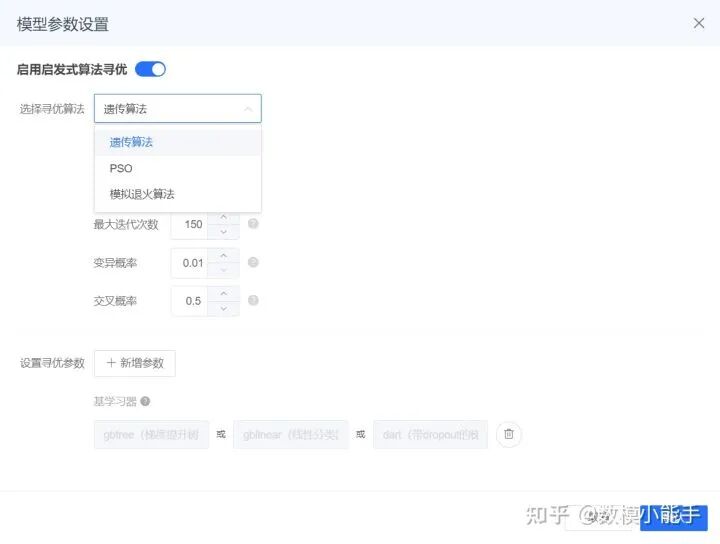 XGBoost分类的启发式算法寻优
XGBoost分类的启发式算法寻优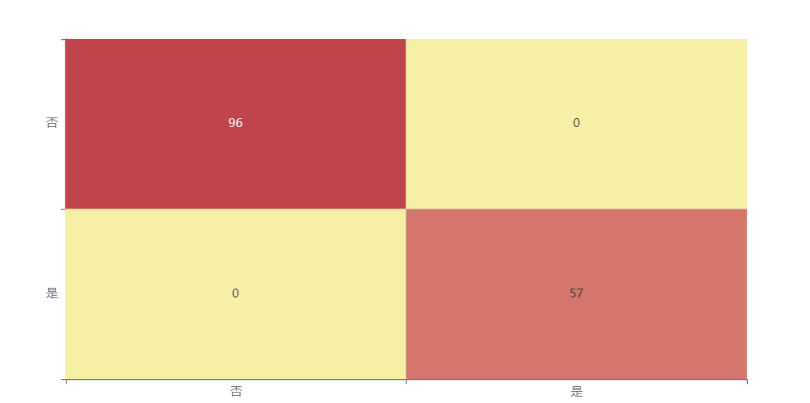 spsspro中的训练数据混淆矩阵热力图
spsspro中的训练数据混淆矩阵热力图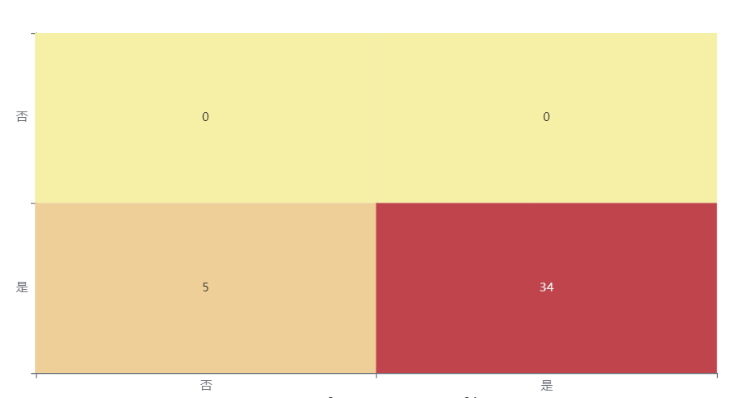 spsspro中的测试数据混淆矩阵热力图
spsspro中的测试数据混淆矩阵热力图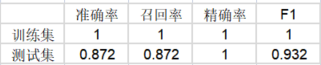 模型评估结果
模型评估结果上表中展示了训练集和测试集的分类评价指标,通过量化指标来衡量决策树对训练、测试数据的分类效果。
● 召回率(recall):实际为正样本的结果中,预测为正样本的比例,召回率越大越好。
● 精确率(f1):预测出来为正样本的结果中,实际为正样本的比例,精确率越大越好。
● F1:精确率和召回率的调和平均,精确率和召回率是互相影响的,虽然两者都高是一种期望的理想情况,然而实际中常常是精确率高、召回率就低,或者召回率低、但精确率高。若需要兼顾两者,那么就可以用F1指标。
可以看到,F1在测试集的效果达到了95%,模型靠谱,可以用于预测。
查看模型输出(这里只看概率),我们可以得到每个模型的【是否违约_否】的概率,这个概率就可以作为信贷风险的量化得分,然后我们这里可以进行归一化,然后按比例分配贷款。
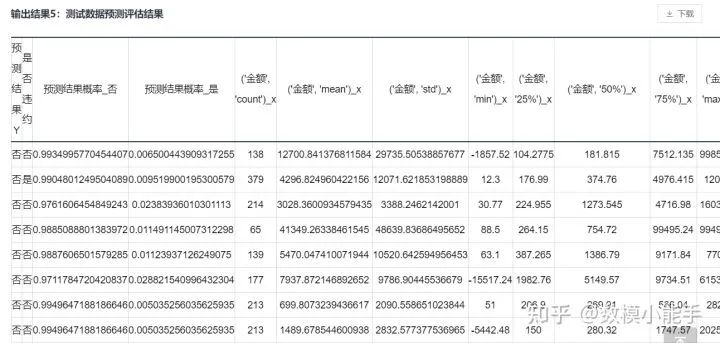
以上方法简单粗暴,如果想要更突出的小伙伴可以使用评分卡或者AHP模型,这里举例AHP模型,信贷风险的评价指标可以分为三个内容:信誉评级,是否违约,企业流水或收入支出比,我们可以设计2个分类模型(是否违约),一个回归模型(企业流水或收入支出比),采用AHP构建判断矩阵(用德尔菲法确定输入,可以不用),然后加权来得出来信贷风险的量化得分。
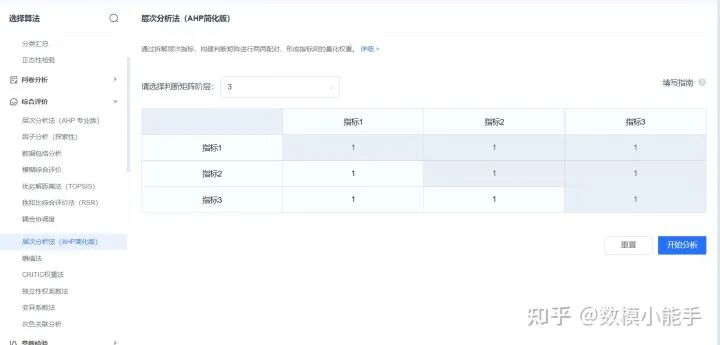 SPSSPRO中的层次分析法(AHP)
SPSSPRO中的层次分析法(AHP)
(2) 在问题1的基础上,对附件2中302家企业的信贷风险进行量化分析,并给出该银行在年度信贷总额为1亿元时对这些企业的信贷策略。
在问题1 的基础上,我们将全部数据投入进行训练,训练好的模型用再使用附件2进行计算。
附件2数据处理对着step1~step6对附件2处理一遍即可。
(3) 企业的生产经营和经济效益可能会受到一些突发因素影响,而且突发因素往往对不同行业、不同类别的企业会有不同的影响。综合考虑附件2中各企业的信贷风险和可能的突发因素(例如:新冠病毒疫情)对各企业的影响,给出该银行在年度信贷总额为1亿元时的信贷调整策略。
这里要求给出信贷调整策略,原因是突发因素会对不同行业、不同类别的企业会有不同的影响,例如对互联网行业,新冠病毒疫情是促进的,但是对于旅游业,新冠病毒疫情则导致了其大萧条。
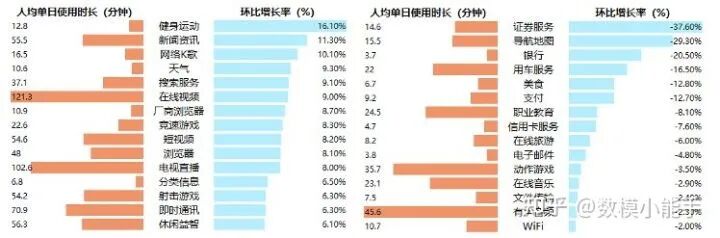 mUserTracker-2020年春节及节前日人均使用时长增长和下降率TOP15行业
mUserTracker-2020年春节及节前日人均使用时长增长和下降率TOP15行业因此这里需要分不同行业来进行调整:
基于企业名的关键词可以得到行业的区分,
 公司的名称
公司的名称区分好行业后,可以通过AHP或者熵值法(需要自行爬取数据)等量化模型对不同行业构建判断矩阵,得到他们的权重比,然后加权在问题2的信贷风险量化得分上,即为一个比较有理,简单的解决方案。
& Y4 c( `% E9 j! }
# w) ^7 d4 Y' K% P. K5 |( b: O# t" I+ `; g/ W5 e, Z2 Q+ N
8 [5 I0 l+ v0 O" A# u7 c6 [
作者: qq_1652401090 时间: 2022-5-18 13:52
6666
Y; F! }8 G b; |4 r/ [2 Z4 i9 y; E
| 欢迎光临 数学建模社区-数学中国 (http://www.madio.net/) |
Powered by Discuz! X2.5 |
