贾 娟,汪斌强 时间:2008年02月25日 % P" U+ w$ Q& |5 d6 T) u " L& O8 Z) C0 J E! X4 i* F6 u 摘 要:针对路由器高可用性系统中心跳探测模块的常见问题,提出一套新型基于网络层自动调频的心跳探测方案。该方案采用双心跳线,结合动态调节探测周期的方法,并在网络层中实现。 $ [$ r( H: U# w. I- \关键词:高可用性 心跳 网络层 & m$ I. A: E. g& S6 C ( @8 V" S. ? r2 M 计算机网络已经成为现代社会生产和生活的基础设施,而核心路由器作为网络的关键结点,能否保证服务的可靠性和稳定性是一个极为重要的问题。核心路由器一般承担着骨干网的运营,如果发生致命故障,将导致大面积网络的瘫痪,造成的直接经济损失也是巨大的。9 x' U( D5 q* M+ t" {
一般的解决方法是采用双机热备的主从切换方式,如CISCO的HRSP协议所介绍的一种方法,由一台active路由器和standby路由器组来承担高可靠性。而本文讨论的是核心路由器如何解决主备主控板的切换来保证高可靠性的问题。这样就产生了一个问题,即如何设计一种及时且准确的探测机制来发现主控板故障,这是能否实现主备切换的基础。 ) j% ^9 U- X! _ 本文就已有的心跳(Heartbeat)探测机制存在的优点和不足进行讨论,并设计了一种基于网络层的可自动调频心跳保障模型。 ) N7 N5 g/ p- K1 ?( E$ ?# k1 Heartbeat介绍 ) _6 l# }* I, I0 V Heartbeat网络是故障发生时系统间的通信通道。简单地说,系统通过心跳网络进行周期性的问候信息交流。系统在正常情况下,备用处理器发送信息询问主用处理器的健康状况,主用处理器同样发送心跳探测包来确定备用处理器是否随时处于等待状态。如果备用处理器在限定的周期内未收到主用处理器的探测包,则表明主用处理器发生故障,它会自动接管主用处理器的IP地址和各种应用服务,成为新的主用处理器。当失效处理器恢复正常后,重新发状态信息给新的主用处理器,要求其成为备用处理器。6 i2 t1 h2 x* V6 A( c; K9 }
现有的心跳网络连接方式多借助于RS232串行线路和以太网方式。由于心跳网络相对于整个网络所传输的数据量要小,但对其可靠性要求很高,即零丢包率,否则连续的数据丢失会引起对方处理器误认为其宕机。因以太网价格低廉、应用广泛、不需要特殊的电缆和硬件设备,所以通常被推荐用来实现心跳网络。此外其他网络介质也没有其传输可靠性高。对于传输大量数据流的情况,推荐使用快速传输网络,但是心跳数据信息相对较小,现有Heartbeat探测主要存在以下问题。 4 z! M) a B2 y _* T (1) 硬件问题造成的误判 # s7 i8 c* W h 主从双处理器的设计目的是为了避免SPOF(单点故障)造成停机。而心跳线同样可以成为SPOF。当处理器收不到对方的心跳信息时,故障原因分为两种,一种是主处理器软硬件的故障;另一种可能是心跳线路自身的故障。对于前一种情况确实应该触发主备切换措施,而第二种情况可能会造成系统误判而进行主备切换,主备处理器切换必然要造成路由器短时间的异常工作,所以确定故障的原因比较困难。 ! U% b6 q! v* q2 T' a% G" E (2) 心跳周期难以设定, V7 p; q1 a7 p5 e ^9 L( J- L3 P1 ^
作为判断故障的心跳模块自身必须可靠稳定,所以一般设计比较简单。而心跳周期长度一般采用人为设置,但是这个周期是否合理?即是否可以及时发现故障,且其发送探测的频率过高又不会造成多余的系统负担。以上两个相互制约的因素都是高可用性要考虑的问题。+ j' D; {5 g3 t9 f/ M# W
在实际应用中,心跳网络一般处于变化的请求服务中,如果系统采用固定心跳周期,有可能弱化系统的可用性;如果周期过短,处理器需要频繁处理心跳探测数据,影响了系统的效率;如果周期过长,在故障发生时,从处理器可能没有及时发现探测心跳未到达而延误触发主备切换模块,造成的网络瘫痪更与高可用性的要求背道而驰。' `( E/ H) x5 |6 |( t
(3) 心跳链路采用套接字以TCP/UDP方式的传输机制造成较大的时延, ~: w2 I( c$ T7 h( i/ l! a# o
作为对实时性和可靠性有双重要求的心跳链路,多数方案都在应用层利用SOCKET以UDP或TCP报文方式实现心跳协议。其中UDP报文比TCP报文简短,正好符合心跳协议的要求。由于UDP没有拥塞控制,所以心跳网络如果出现拥塞,UDP会丢弃一些数据包,但不会影响处理器发送心跳的速率,同时也带来不可靠传输的问题。如果网络在拥塞情况下会丢失一些数据包,这对于零丢包率的心跳检测将造成很大影响。2 S% T* @8 j+ ?% C
在传输速率问题上,无论对于TCP还是UDP的套接字,实现方式都在应用层实现,即心跳报文要经过传输层、内核及接口,并受到应用层任务切换的影响,这样会导致切换时间长达数秒,难以满足实时性的要求。 " j. d+ T2 S* X4 F: w+ ^* m8 \ 在可靠性问题上,如果是单对心跳网络,则可以对探测包进行编号,并利用判别机制裁决。忽略收到非连续编号的数据包的情况,判断因为心跳网络拥塞所致,而不影响心跳信任级别的周期。但如果采用双心跳线网络,在两条链路上同时出现拥塞情况的可能性较小,因而避免了由于不可靠传输造成的误判。 `4 J! b5 l4 R( V, w4 q# S5 n+ F 2 自动调频双心跳保障模型设计方案% I, \2 Q+ Y$ u z9 E
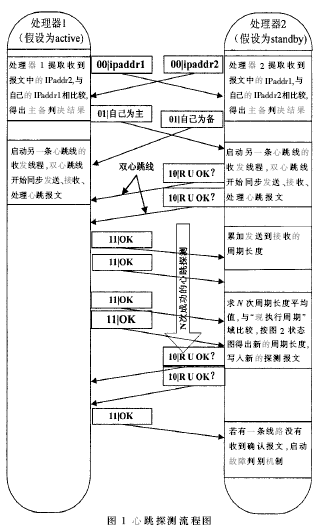
根据上述在心跳探测技术中出现的问题,笔者提出一种基于网络层的自动调频双心跳保障方案。此方案流程如图1,图中的报文类型见表1。5 q" X3 Q |$ f' ~+ B
' ~' c4 ~( C- ]) ]
7 L. s! Z' R5 o. W! {0 V
( b3 d8 t/ R/ W" @: Y l
在路由器启动后,两块处理器均属于初始状态,这时尚未确定active和standby。首先仅在一条心跳线上启动主备协商机制。要求主备协商机制要简约,因为在这里没有必要设计复杂的算法选出主用。因而采取比较两处理板IP地址大小的判决方法,通过互发心跳探测报文,比较IP ADDR值,较小的为主处理器,进入active状态;较大的为备用处理器,进入standby状态。' @2 A; c1 ~ Q W. F
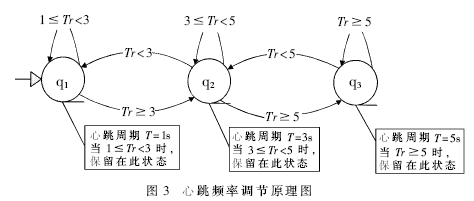
在确定了主备用地位的同时,向对方通告自己的身份。这时启动双心跳线,备用一方发送心跳探测报文监控主用的工作是否正常;主用收到探测报文进行回复。备用在工作时要根据主用发送回复的周期值,计算出系统最合适的心跳探测频率,后文将详细介绍。为了避免由于心跳线发生故障造成的误判,如果备用只收到来自一条心跳线的回复报文,则由故障判别机制来确认主用工作正常。 : Y6 k3 f# F' U* M4 @ 报文类型:00为主备协商报文,DATA域携带处理器IP地址;01为主备确定报文,DATA域携带裁决结果;10为心跳探测报文,standby→active,要求active给确认;11为心跳回应报文,active→standby,告诉standby自己正常。1 q# Z! \" a# ]; h3 N 2.1 双心跳网络探测机制及故障辨别机制 2 l' F. n3 v" f8 L1 l 分别由两个进程各自控制两条心跳线路上的心跳数据发送,由故障判别机制判断处理器的工作状态。例如,若从处理器收到来自两条链路的心跳信息,则判断主处理器为正常工作状态;若从处理器只收到一条链路上的心跳信息,则判断主处理器工作正常,且心跳线故障,不触发主备切换模块;若从处理器未收到任意一条线路的心跳信息,则判断主处理器失效,触发主备切换模块。此设计虽然增加了实现的复杂性,但却解决了实际工程中接口松动等问题造成的系统误判和不必要的消耗。双心跳网络探测机制如图2所示。








 IP卡
IP卡 狗仔卡
狗仔卡









 发表于 2010-4-16 20:00
发表于 2010-4-16 20:00




 转播
转播 淘帖
淘帖 分享
分享 收藏
收藏 支持
支持 反对
反对 微信
微信 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 抢沙发
抢沙发 显身卡
显身卡



